Android Binder机制相关的灵魂发问
Binder机制是Android系统中最重要的系统机制之一,关于Binder机制的细节问题更是多入牛毛。对于常见的一些问题整理如下:
为什么要引入多进程
第一点:Android系统为每个APP会分配固定大小的内存。如果一个APP需要更多的内存空间,要么就可以引入多进程,让某些模块运行在另外的进程中,获取更大的内存;
第二点:由于每个APP运行在不同的进程中,若共享APP中的某些数据的时候,例如通讯录等。
Android中常见的跨进程通信(IPC)的方式
- Bundle:常用于四大组件之间的通信,实现了Parcelable接口;
- ContentProvider:存储和获取数据,不同APP之间共享数据;
- 文件共享:常用于无并发,交换数据实时性不高;
- Messenger:在不同进程通过Message传输,只支持Bundle支持的数据类型,不支持RPC(远程过程调用:Client调用Server的方法);低并发的一对多的串行通信(串行的方式接收Client发出的消息);最底层基于AIDL;
- AIDL:一对多并发通信(Server支持同时处理大量消息),支持RPC;
- Socket:网络数据交换
什么是Binder
在Linux系统中,会将虚拟空间分为用户空间和内核空间。系统每启动一个APP,就会给APP在用户空间创建一个进程;由于Android系统对每个APP是有内存限制,如果想给该APP申请更大的内存,同样也可以在该APP中额外创建一个进程来运行其他模块。
由于进程间是不能互相访问的,只能通过内核空间进行中转,而Binder机制就是Android系统中的一种跨进程通信的方式。
Binder机制需要四部分组成:Server、Client、ServiceManager以及Binder驱动。前三个运行在用户空间,Binder驱动运行在内核空间。Server、Client、ServiceManager之间进行数据通信,都需要通过Binder驱动进行中转。
相对于Linux其他IPC方式来说,Binder机制只需要拷贝一次数据,并且在用Binder驱动传递数据的时候,分配和传输数据一样大的内存,节省了内存和时间。(因为Linux系统的其他IPC因为不知道传输数据的大小,所以目标进程为了能够有足够的空间来存放数据,通常会分配尽可能大的空间;或者有的IPC通过先解析消息头的信息来获取消息体的大小,例如Socket,浪费空间或时间)。
ServiceManager进程
用来管理Service的注册和查询。将字符串转换层对应的Binder引用。该进程为系统启动的时候,有init进程创建出来的。在ServiceManager进程创建的过程中,会执行两步操作:
- 第一步:通过binder_open()打开“/dev/binder”设备文件,获取一个文件描述符,才可以与Binder驱动进行交互;
- 第二步:通过mmap将该设备文件映射到用户空间的虚拟内存,同时系统调用到内核,也在内核空间分配虚拟内存,同时申请一块物理内存,同时映射到用户空间对应的虚拟内存和内核空间对应的虚拟内存中;
- 第三步:通过ioctl发送指令,告诉Binder驱动,该进程为ServiceManager进程;
- 第四步:通过binder_loop(),开启一个循环,时刻等待Binder驱动发送过来的消息;
- 第五步:当接收Binder驱动发送的消息时,通过binder_parse()解析和处理消息。
Client进程
通常APP进程会作为Client进程。
当Android系统启动的时候,启动的第一个用户进程为init进程,init进程fork出Zygote进程,Android的其他进程都是有Zygote进程fork出来的。
一个进程要经历创建、初始化以及加载功能。那么Zygote进程有init进程创建出来的,在完成初始化加载功能的时候,会创建一个Socket通信的ZygoteServer,用来接收AMS发出创建进程的请求;同时fork出system_server进程,完成system_server进程初始化、功能加载:system_server进程主要就是启动一些系统Service,如AMS、PMS、WMS等。
当Zygote进程接收到AMS创建APP进程的时候,维护的循环中就会通过Zygote进程fork出一个进程,完成APP进程的初始化、功能加载:主要加载了APP的入口类ActivityThread,通过维护的循环消息机制来完成对Activity、Broadcast、Service等操作。
APP进程需要通过Binder驱动与其他进程通信,同样需要获取“/dev/binder”设备文件的描述符,并且在用户空间分配虚拟内存,在内核空间对应分配虚拟内存,同时申请一块物理内存,完成映射。区别于ServiceManager进程,该APP进程会设置Binder驱动的最大连接数,默认的为15个,只会创建binder主线程,其他的线程有Binder驱动来控制创建。
Server进程
在APP中都是通过AMS来启动Service,在启动Service之前会判断该Service的进程是否和APP的进程一致,如果跟APP的进程一致,则直接通过ActivityThread中维护的消息队列来启动该Service;如果不在APP的进程中,则会通过AMS的startProcessLocked(),最终将进程的信息写入到与Zygote进程的socket通道中,Zygote进程收到消息之后,同样会通过Zygote进程fork出一个进程,并完成该进程的初始化、功能加载,同样也是加载了一个ActivityThread类。
只不过bindService在创建完进程之后,还会发送通过ActivityThread的消息机制完成Service的bind过程。
扩展几个小问题:
1.为什么Zygote进程与system_server进程之间的通信采用Socket,而不是Binder
- (1)Binder机制的前提的是ServiceManager进程创建出来,而SeviceManager进程和Zygote进程都是有init进程创建的,并且Zygote进程会先在ServiceManager进程前面一点点,而Zygote进程在fork出system_server进程的进程的时候,不能完全保证ServiceManager进程已经创建完。
- (2)Zygote进程与system_server进程之间的socket的所有者是root,group是system,只有系统权限的用户才能读写,增加了安全保障。
2.为什么Zygote进程是fork出APP或者Service进程,而不是新建进程
每个APP都运行在各自的Dalivk虚拟机中,APP每次启动的时候都要初始化和启动虚拟机,这个过程会很费时间。而Zygote进程通过fork把已经运行的虚拟机和内存信息共享,可以预加载资源和类,缩短启动时间
Binder机制中的一次拷贝原理
进程之间使用Binder驱动来进行通信,需要首先获取一个dev/binder设备文件的文件描述符,才可以与Binder驱动交互。Binder驱动会为每个进程创建一个binder_proc的结构体,然后将该结构体放到全局的hash队列binder_procs中,只要遍历该队列,就知道当前有多少进程在使用Binder通信。
其次还需要利用mmap内存映射,可以将/dev/binder设备文件映射到用户空间的虚拟内存中。系统在为该文件内存映射的时候,不仅在用户空间分配虚拟内存,并且还会在内核空间分配虚拟内存,并且Kernel还会申请一块物理内存同时映射到用户空间对应的虚拟内存和在内核空间对应的虚拟内存;这样如果将数据拷贝到用户空间,都是相当于拷贝到内核空间,反之亦然。
在将数据从发送进程传递到目标进程的时候:
- (1)首先将数据从发送进程的用户空间对应的虚拟内存拷贝到内核空间对应的虚拟内存中;
- (2)然后使用Binder驱动传递数据的时候,Binder驱动会为该数据创建一个数据接收缓冲区,而该缓冲区是从目标进程在内核空间对应的虚拟内存开始分配虚拟内存,那么当把数据从发送进程对应的虚拟内存拷贝到Binder驱动的数据缓冲区的时候,其实就相当于直接拷贝到目标进程在内核空间对应的虚拟内存中。
- (3)由于前面创建目标进程的时候,由于进程在用户空间分配的虚拟内存和在内核空间对应的虚拟内存存在映射关系,实际上上面的过程就是直接拷贝到了目标进程在用户空间分配的虚拟内存中。
- (4)目标进程将数据从内核空间对应的虚拟内存拷贝到用户空间对应的虚拟内存。
这样就完成了Binder机制中的一次拷贝,我觉得所谓的Binder机制的一次拷贝,指的是用Binder驱动传递数据的时候只需要拷贝一次数据。
AIDL中的代理模式
两个进程之间的跨进程通信必须通过Binder驱动进行中转。在应用层创建的AIDL文件,最终会将该文件编译成一个java文件。该文件包括三部分的内容:
- (1)公共接口:制定Server进程所要实现功能的标准,为代理模式的公共接口;
- (2)Stub:继承Binder,用于Server进程来访问Binder驱动;实现公共接口的抽象类(这里还是一个适配器模式),实现公共接口的具体功能,为代理模式的被代理类;
- (3)Stub.Proxy:实现公共接口,并持有Stub的对象(这个只不过是Binder驱动的本地对象BinderProxy,该BinderProxy对象用于Client进程来访问Binder驱动),实现两个进程的RPC,为代理模式的代理类。
AIDL的跨进程具体实现过程
AIDL服务是应用层的Service,区别与系统Service,系统Service是通过ServiceManager进程来管理,而应用Service是通过AMS来管理。
Client和Server之所以能够实现跨进程通信,都是通过Binder驱动进行中转。Android系统在Framework层和Native层对Binder驱动进行封装,使得应用层可以通过API调用到Binder驱动。
在native层封装体现:
- (1)进程在Native层会通过ProcessState初始化进程主要会完成下面内容:
通过ProcessState来获取Binder驱动的设备文件”/dev/binder”的文件描述符,完成内存映射;
开启Binder线程池,创建线程池中的第一个Binder主线程IPCThreadState;
在该Binder主线程中维护一个循环,来读取Binder驱动发送过来的消息。 - (2)Binder驱动在向进程中binder_read_thread的时候,都会先看下有没有空闲的Binder线程,如果没有则通知ProcesState的Binder线程池创建一个Binder非主线程来发送消息;
- (3)进程通过IPCThreadState调用ioctl来与Binder驱动进行传递信息。Client进程通过BpBinder来调用到ioctl完成向Binder驱动发送数据,而在Server进程通过BBinder,准确的说是JavaBBinder完成向Binder驱动发送数据。
在应用层主要是通过Framework封装的API来完成IPC的,在Framework层封装体现: - (1)Client通过bindService将ServiceConnection给到Server,当Server创建成功的时候,通过onBind将BinderProxy返回给Client;
- (2)在Client进程就是通过BinderProxy来向Binder驱动发送数据,在Server进程会继承Stub,也是Binder的子类,通过Binder来向Binder驱动传递数据;
当Client要访问Server进程的RPC(Remote Process Call远程过程调用)的时候: - (1)Client进程调用BinderProxy的transact(),通过jni调用到BpBinder的transact(),然后调用到IPCThreadState向Binder驱动发送数据;
- (2)Binder驱动接收到Client进程发送的指令的时候,就会通过BBinder的ransact()调用到JavaBBinder的onTransact(),通过jni调用到Server进程的Binder的onTransact(),最终调用到Stub中对应的接口方法,完成RPC。
Binder如何精确制导,找到目标Binder实体,并唤醒进程或者线程
Binder实体服务其实有两种,一是通过addService注册到ServiceManager中的服务,比如ActivityManagerService、PackageManagerService、PowerManagerService等,一般都是系统服务;还有一种是通过bindService拉起的一些服务,一般是开发者自己实现的服务。这里先看通过addService添加的被ServiceManager所管理的服务。有很多分析ServiceManager的文章,本文不分析ServiceManager,只是简单提一下,ServiceManager是比较特殊的服务,所有应用都能直接使用,因为ServiceManager对于Client端来说Handle句柄是固定的,都是0,所以ServiceManager服务并不需要查询,可以直接使用。
理解Binder定向制导的关键是理解Binder的四棵红黑树,先看一下binder_proc结构体,在它内部有四棵红黑树,threads,nodes,refs_by_desc,refs_by_node,nodes就是Binder实体在内核中对应的数据结构,binder_node里记录进程相关的binder_proc,还有Binder实体自身的地址等信息,nodes红黑树位于binder_proc,可以知道Binder实体其实是进程内可见,而不是线程内。
1 | struct binder_proc { |
现在假设存在一堆Client与Service,Client如何才能访问Service呢?首先Service会通过addService将binder实体注册到ServiceManager中去,Client如果想要使用Servcie,就需要通过getService向ServiceManager请求该服务。在Service通过addService向ServiceManager注册的时候,ServiceManager会将服务相关的信息存储到自己进程的Service列表中去,同时在ServiceManager进程的binder_ref红黑树中为Service添加binder_ref节点,这样ServiceManager就能获取Service的Binder实体信息。而当Client通过getService向ServiceManager请求该Service服务的时候,ServiceManager会在注册的Service列表中查找该服务,如果找到就将该服务返回给Client,在这个过程中,ServiceManager会在Client进程的binder_ref红黑树中添加binder_ref节点,可见本进程中的binder_ref红黑树节点都不是本进程自己创建的,要么是Service进程将binder_ref插入到ServiceManager中去,要么是ServiceManager进程将binder_ref插入到Client中去。之后,Client就能通过Handle句柄获取binder_ref,进而访问Service服务。
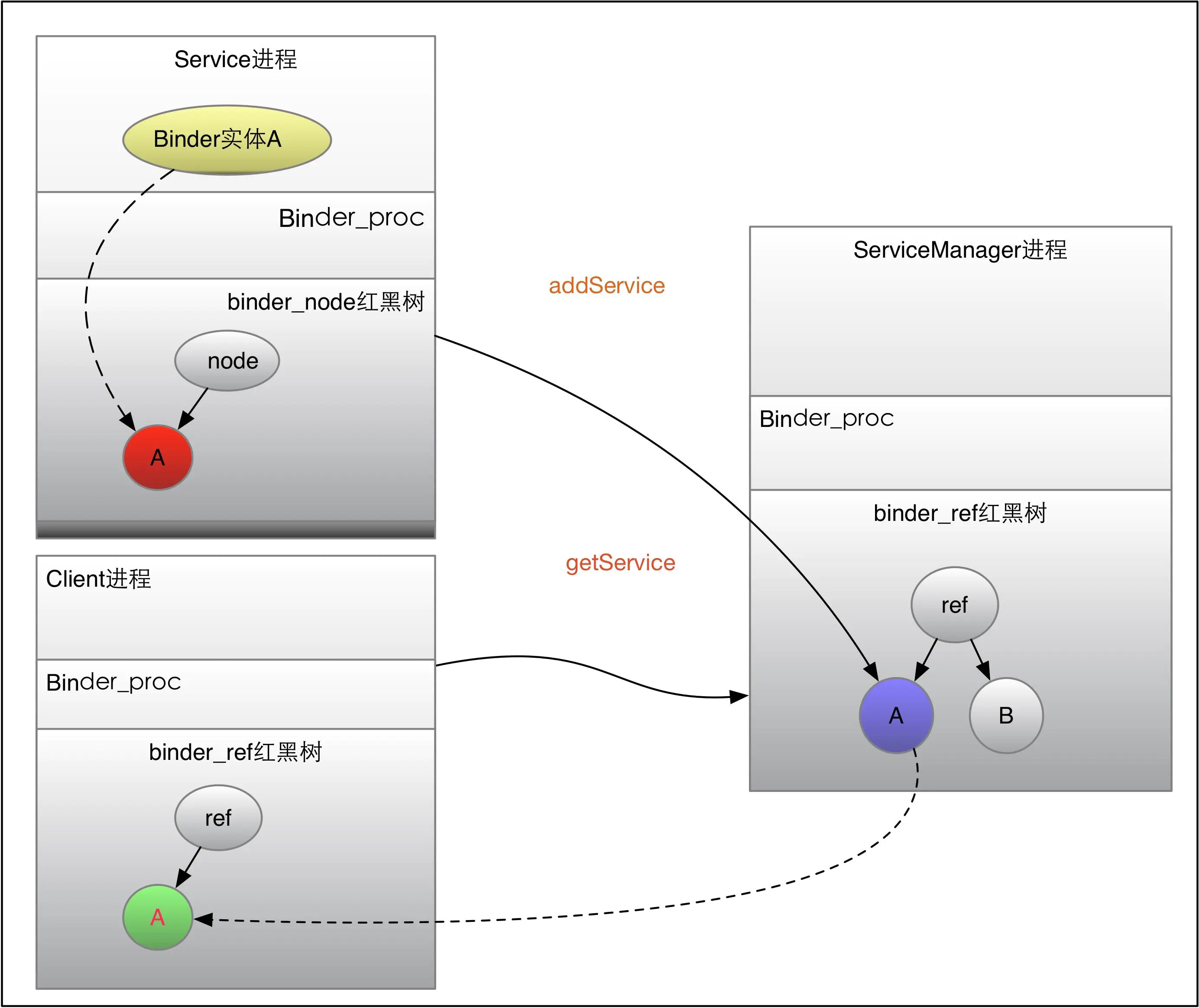
binder_ref添加逻辑
getService之后,便可以获取binder_ref引用,进而获取到binder_proc与binder_node信息,之后Client便可有目的的将binder_transaction事务插入到binder_proc的待处理列表,并且,如果进程正在睡眠,就唤起进程,其实这里到底是唤起进程还是线程也有讲究,对于Client向Service发送请求的状况,一般都是唤醒binder_proc上睡眠的线程:
1 | struct binder_ref { |
binder_proc为何会有两棵binder_ref红黑树
binder_proc中存在两棵binder_ref红黑树,其实两棵红黑树中的节点是复用的,只是查询方式不同,一个通过handle句柄,一个通过node节点查找。个人理解:refs_by_node红黑树主要是为了
binder驱动往用户空间写数据所使用的,而refs_by_desc是用户空间向Binder驱动写数据使用的,只是方向问题。比如在服务addService的时候,binder驱动会在在ServiceManager进程的binder_proc中查找binder_ref结构体,如果没有就会新建binder_ref结构体,再比如在Client端getService的时候,binder驱动会在Client进程中通过 binder_get_ref_for_node为Client创建binder_ref结构体,并分配句柄,同时插入到refs_by_desc红黑树中,可见refs_by_node红黑树,主要是给binder驱动往用户空间写数据使用的。相对的refs_by_desc主要是为了用户空间往binder驱动写数据使用的,当用户空间已经获得Binder驱动为其创建的binder_ref引用句柄后,就可以通过binder_get_ref从refs_by_desc找到响应binder_ref,进而找到目标binder_node。可见有两棵红黑树主要是区分使用对象及数据流动方向,看下面的代码就能理解:
1 | // 根据32位的uint32_t desc来查找,可以看到,binder_get_ref不会新建binder_ref节点 |
可以看到binder_get_ref并具备binder_ref的创建功能,相对应的看一下binder_get_ref_for_node,binder_get_ref_for_node红黑树主要通过binder_node进行查找,如果找不到,就新建binder_ref,同时插入到两棵红黑树中去
1 | static struct binder_ref *binder_get_ref_for_node(struct binder_proc *proc, |
该函数调用在binder_transaction函数中,其实就是在binder驱动访问target_proc的时候,这也也很容易理解,Handle句柄对于跨进程没有任何意义,进程A中的Handle,放到进程B中是无效的。
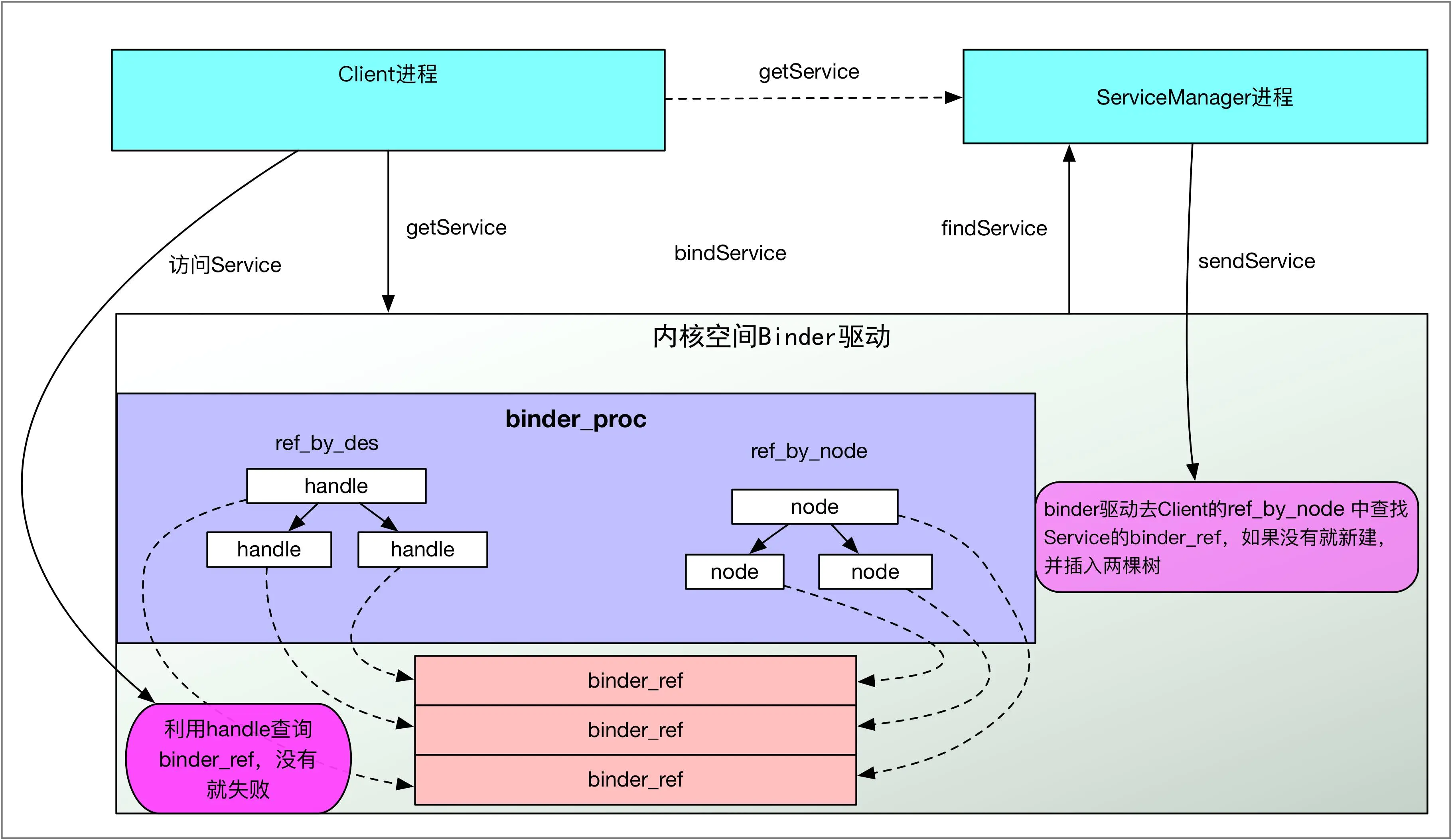
两棵binder_ref红黑树
Binder一次拷贝原理
Android选择Binder作为主要进程通信的方式同其性能高也有关系,Binder只需要一次拷贝就能将A进程用户空间的数据为B进程所用。这里主要涉及两个点:
Binder的map函数,会将内核空间直接与用户空间对应,用户空间可以直接访问内核空间的数据
A进程的数据会被直接拷贝到B进程的内核空间(一次拷贝)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
ProcessState::ProcessState()
: mDriverFD(open_driver())
, mVMStart(MAP_FAILED)
, mManagesContexts(false)
, mBinderContextCheckFunc(NULL)
, mBinderContextUserData(NULL)
, mThreadPoolStarted(false)
, mThreadPoolSeq(1){
if (mDriverFD >= 0) {
....
// mmap the binder, providing a chunk of virtual address space to receive transactions.
mVMStart = mmap(0, BINDER_VM_SIZE, PROT_READ, MAP_PRIVATE | MAP_NORESERVE, mDriverFD, 0);
...
}
}
mmap函数属于系统调用,mmap会从当前进程中获取用户态可用的虚拟地址空间(vm_area_struct *vma),并在mmap_region中真正获取vma,然后调用file->f_op->mmap(file, vma),进入驱动处理,之后就会在内存中分配一块连续的虚拟地址空间,并预先分配好页表、已使用的与未使用的标识、初始地址、与用户空间的偏移等等,通过这一步之后,就能把Binder在内核空间的数据直接通过指针地址映射到用户空间,供进程在用户空间使用,这是一次拷贝的基础,一次拷贝在内核中的标识如下:
1 | struct binder_proc { |
上面只是在APP启动的时候开启的地址映射,但并未涉及到数据的拷贝,下面看数据的拷贝操作。当数据从用户空间拷贝到内核空间的时候,是直从当前进程的用户空间接拷贝到目标进程的内核空间,这个过程是在请求端线程中处理的,操作对象是目标进程的内核空间。看如下代码:
1 | static void binder_transaction(struct binder_proc *proc, |
可以看到binder_alloc_buf(target_proc, tr->data_size,tr->offsets_size, !reply && (t->flags & TF_ONE_WAY))函数在申请内存的时候,是从target_proc进程空间中去申请的,这样在做数据拷贝的时候copy_from_user(t->buffer->data, tr->data.ptr.buffer, tr->data_size)),就会直接拷贝target_proc的内核空间,而由于Binder内核空间的数据能直接映射到用户空间,这里就不在需要拷贝到用户空间。这就是一次拷贝的原理。内核空间的数据映射到用户空间其实就是添加一个偏移地址,并且将数据的首地址、数据的大小都复制到一个用户空间的Parcel结构体,具体可以参考Parcel.cpp的Parcel::ipcSetDataReference函数。
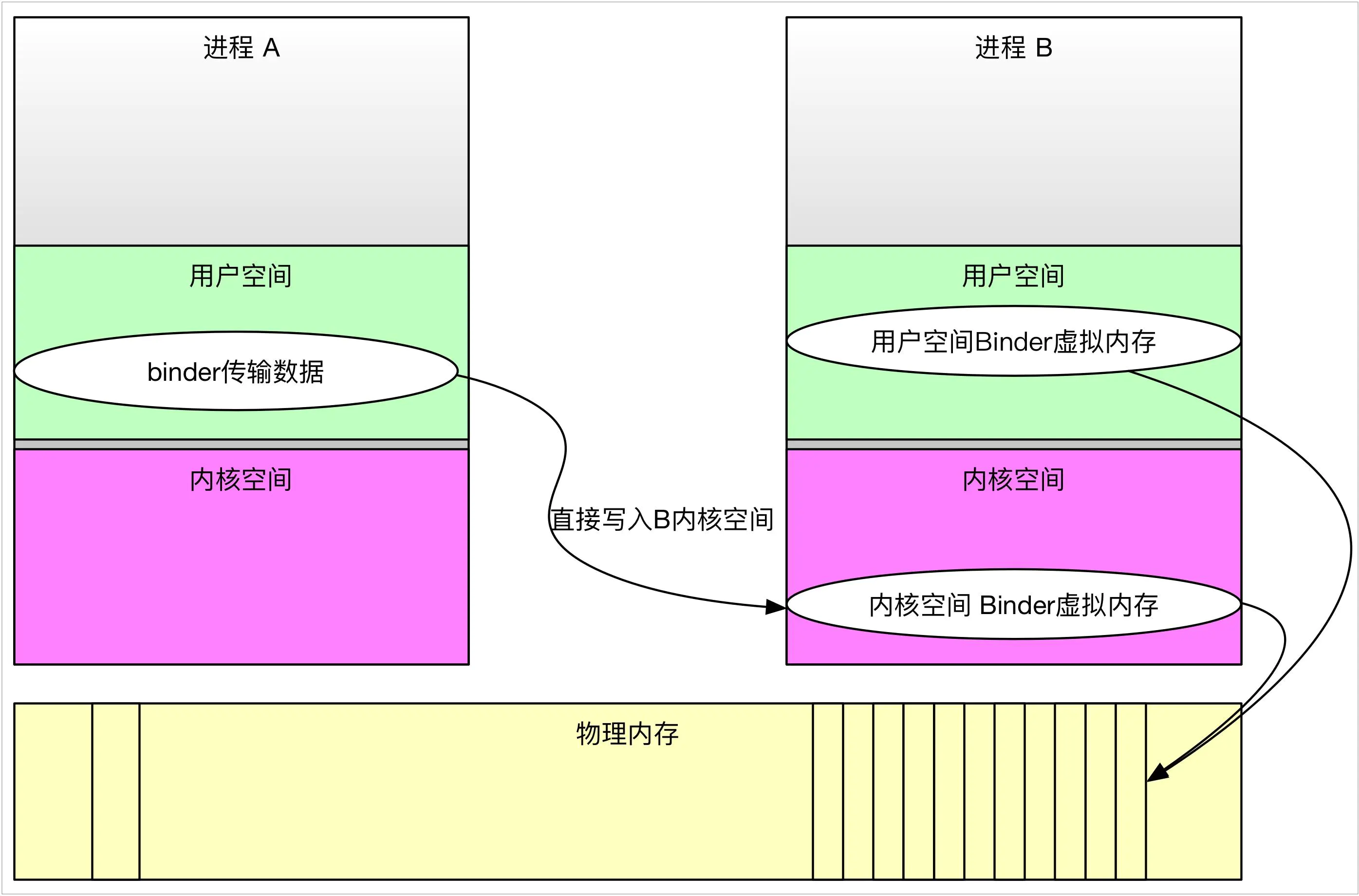
Binder一次拷贝原理.jpg
Binder传输数据的大小限制
虽然APP开发时候,Binder对程序员几乎不可见,但是作为Android的数据运输系统,Binder的影响是全面性的,所以有时候如果不了解Binder的一些限制,在出现问题的时候往往是没有任何头绪,比如在Activity之间传输BitMap的时候,如果Bitmap过大,就会引起问题,比如崩溃等,这其实就跟Binder传输数据大小的限制有关系,在上面的一次拷贝中分析过,mmap函数会为Binder数据传递映射一块连续的虚拟地址,这块虚拟内存空间其实是有大小限制的,不同的进程可能还不一样。
普通的由Zygote孵化而来的用户进程,所映射的Binder内存大小是不到1M的,准确说是 110241024) - (4096 *2) :这个限制定义在ProcessState类中,如果传输说句超过这个大小,系统就会报错,因为Binder本身就是为了进程间频繁而灵活的通信所设计的,并不是为了拷贝大数据而使用的:
1 |
而在内核中,其实也有个限制,是4M,不过由于APP中已经限制了不到1M,这里的限制似乎也没多大用途:
1 | static int binder_mmap(struct file *filp, struct vm_area_struct *vma) |
有个特殊的进程ServiceManager进程,它为自己申请的Binder内核空间是128K,这个同ServiceManager的用途是分不开的,ServcieManager主要面向系统Service,只是简单的提供一些addServcie,getService的功能,不涉及多大的数据传输,因此不需要申请多大的内存:
1 | int main(int argc, char **argv) |
系统服务与bindService等启动的服务的区别
服务可分为系统服务与普通服务,系统服务一般是在系统启动的时候,由SystemServer进程创建并注册到ServiceManager中的。而普通服务一般是通过ActivityManagerService启动的服务,或者说通过四大组件中的Service组件启动的服务。这两种服务在实现跟使用上是有不同的,主要从以下几个方面:
- 服务的启动方式
- 服务的注册与管理
- 服务的请求使用方式
首先看一下服务的启动上,系统服务一般都是SystemServer进程负责启动,比如AMS,WMS,PKMS,电源管理等,这些服务本身其实实现了Binder接口,作为Binder实体注册到ServiceManager中,被ServiceManager管理,而SystemServer进程里面会启动一些Binder线程,主要用于监听Client的请求,并分发给响应的服务实体类,可以看出,这些系统服务是位于SystemServer进程中(有例外,比如Media服务)。在来看一下bindService类型的服务,这类服务一般是通过Activity的startService或者其他context的startService启动的,这里的Service组件只是个封装,主要的是里面Binder服务实体类,这个启动过程不是ServcieManager管理的,而是通过ActivityManagerService进行管理的,同Activity管理类似。
再来看一下服务的注册与管理:系统服务一般都是通过ServiceManager的addService进行注册的,这些服务一般都是需要拥有特定的权限才能注册到ServiceManager,而bindService启动的服务可以算是注册到ActivityManagerService,只不过ActivityManagerService管理服务的方式同ServiceManager不一样,而是采用了Activity的管理模型,详细的可以自行分析
最后看一下使用方式,使用系统服务一般都是通过ServiceManager的getService得到服务的句柄,这个过程其实就是去ServiceManager中查询注册系统服务。而bindService启动的服务,主要是去ActivityManagerService中去查找相应的Service组件,最终会将Service内部Binder的句柄传给Client。
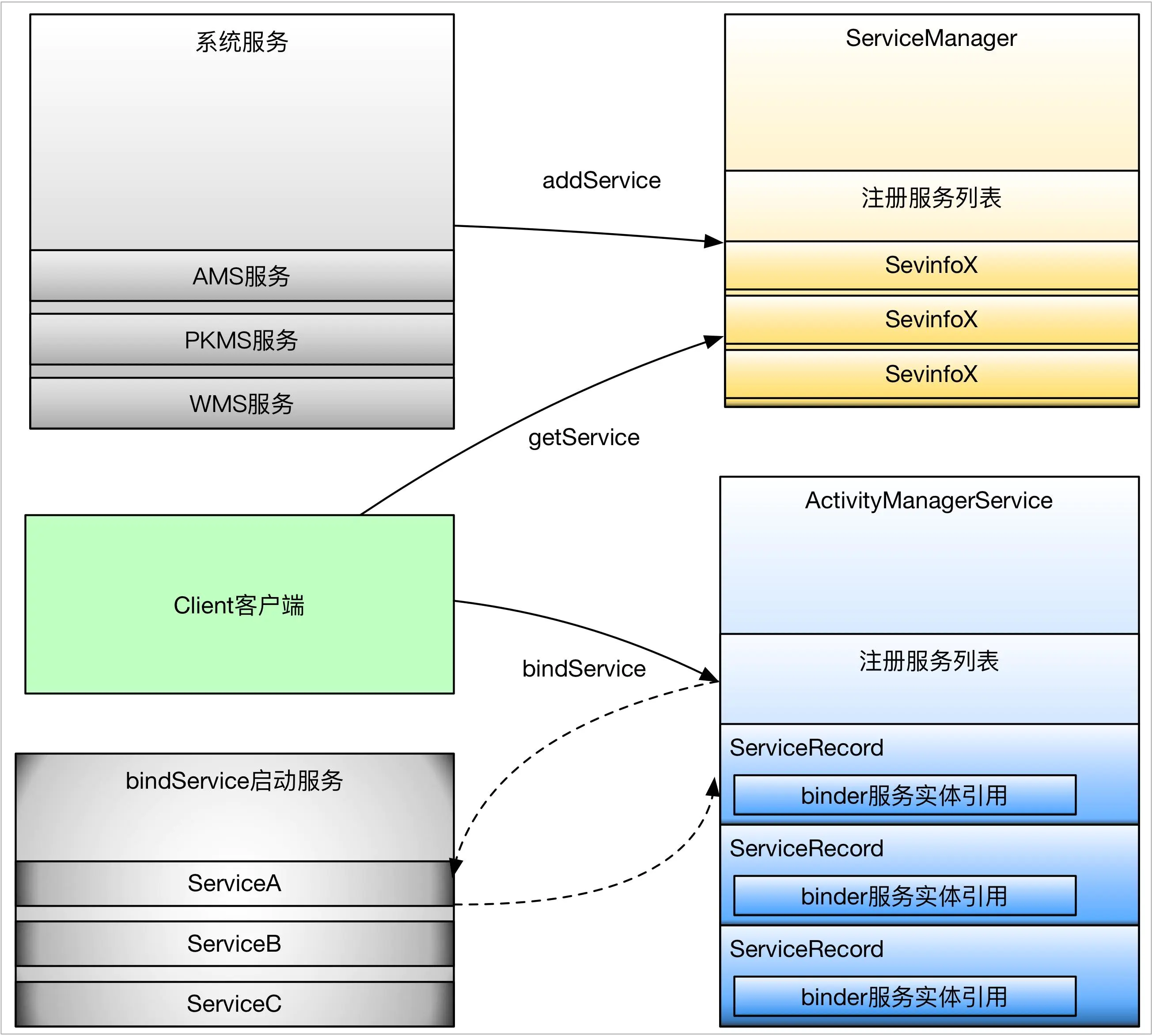
系统服务与bindService启动服务的区别.jpg
Binder线程、Binder主线程、Client请求线程的概念与区别
Binder线程是执行Binder服务的载体,只对于服务端才有意义,对请求端来说,是不需要考虑Binder线程的,但Android系统的处理机制其实大部分是互为C/S的。比如APP与AMS进行交互的时候,都互为对方的C与S,这里先不讨论这个问题,先看Binder线程的概念。
Binder线程就是执行Binder实体业务的线程,一个普通线程如何才能成为Binder线程呢?很简单,只要开启一个监听Binder字符设备的Loop线程即可,在Android中有很多种方法,不过归根到底都是监听Binder,换成代码就是通过ioctl来进行监听。
拿ServerManager进程来说,其主线就是Binder线程,其做法是通过binder_loop实现不死线程:
1 | void binder_loop(struct binder_state *bs, binder_handler func) |
上面的关键代码1就是阻塞监听客户端请求,2 就是处理请求,并且这是一个死循环,不退出。再来看SystemServer进程中的线程,在Android4.3(6.0以后打代码就不一样了)中SystemSever主线程便是Binder线程,同时一个Binder主线程,Binder线程与Binder主线程的区别是:线程是否可以终止Loop,不过目前启动的Binder线程都是无法退出的,其实可以全部看做是Binder主线程,其实现原理是,在SystemServer主线程执行到最后的时候,Loop监听Binder设备,变身死循环线程,关键代码如下:
1 | extern "C" status_t system_init() |
ProcessState::self()->startThreadPool()是新建一个Binder主线程,而PCThreadState::self()->joinThreadPool()是将当前线程变成Binder主线程。其实startThreadPool最终也会调用joinThreadPool,看下其关键函数:
1 | void IPCThreadState::joinThreadPool(bool isMain) |
先看关键点1 talkWithDriver,其实质还是去掉用ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr) >= 0)去不断的监听Binder字符设备,获取到Client传输的数据后,再通过executeCommand去执行相应的请求,joinThreadPool是普通线程化身Binder线程最常见的方式。不信,就再看一个MediaService,看一下main_mediaserver的main函数:
1 | int main(int argc, char** argv) |
其实还是通过joinThreadPool变身Binder线程,至于是不是主线程,看一下下面的函数:
1 | void IPCThreadState::joinThreadPool(bool isMain) |
其实关键就是就是传递给joinThreadPool函数的isMain是否是true,不过是否是Binder主线程并没有什么用,因为源码中并没有为这两者的不同处理留入口,感兴趣可以去查看一下binder中的TIMED_OUT。
最后来看一下普通Client的binder请求线程,比如我们APP的主线程,在startActivity请求AMS的时候,APP的主线程成其实就是Binder请求线程,在进行Binder通信的过程中,Client的Binder请求线程会一直阻塞,知道Service处理完毕返回处理结果。
Binder请求的同步与异步
很多人都会说,Binder是对Client端同步,而对Service端异步,其实并不完全正确,在单次Binder数据传递的过程中,其实都是同步的。只不过,Client在请求Server端服务的过程中,是需要返回结果的,即使是你看不到返回数据,其实还是会有个成功与失败的处理结果返回给Client,这就是所说的Client端是同步的。至于说服务端是异步的,可以这么理解:在服务端在被唤醒后,就去处理请求,处理结束后,服务端就将结果返回给正在等待的Client线程,将结果写入到Client的内核空间后,服务端就会直接返回了,不会再等待Client端的确认,这就是所说的服务端是异步的,可以从源码来看一下:
Client端同步阻塞请求
1
2
3
4
5
6
7status_t IPCThreadState::transact(int32_t handle,
uint32_t code, const Parcel& data,
Parcel* reply, uint32_t flags)
{
if (reply) {
err = waitForResponse(reply);
} ...
Client在请求服务的时候 Parcel* reply基本都是非空的(还没见过空用在什么位置),非空就会执行waitForResponse(reply),如果看过几篇Binder分析文章的人应该都会知道,在A端向B写完数据之后,A会返回给自己一个BR_TRANSACTION_COMPLETE命令,告知自己数据已经成功写入到B的Binder内核空间中去了,如果是需要回复,在处理完BR_TRANSACTION_COMPLETE命令后会继续阻塞等待结果的返回:
1 | status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult){ |
关键点1就是处理BR_TRANSACTION_COMPLETE,如果需要等待reply,还要通过talkWithDriver等待结果返回,最后执行关键点2,处理返回数据。对于服务端来说,区别就在于关键点1,来看一下服务端Binder线程的代码,拿常用的joinThreadPool来看,在talkWithDriver后,会执行executeCommand函数,
1 | void IPCThreadState::joinThreadPool(bool isMain) |
executeCommand会进一步调用sendReply函数,看一下这里的特点waitForResponse(NULL, NULL),这里传递的都是null,在上面的关键点1的地方我们知道,这里不需要等待Client返回,因此会直接 goto finish,这就是所说的Client同步,而服务端异步的逻辑。
1 | // BC_REPLY |
1 | case BR_TRANSACTION_COMPLETE: |
请求同步最好的例子就是在Android6.0之前,国产ROM权限的申请都是同步的,在申请权限的时候,APP申请权限的线程会阻塞,就算是UI线程也会阻塞,ROM为了防止ANR,都会为权限申请设置一个倒计时,不操作,就给个默认操作,有兴趣可以自己分析。
Android APP进程天生支持Binder通信的原理是什么
Android APP进程都是由Zygote进程孵化出来的。常见场景:点击桌面icon启动APP,或者startActivity启动一个新进程里面的Activity,最终都会由AMS去调用Process.start()方法去向Zygote进程发送请求,让Zygote去fork一个新进程,Zygote收到请求后会调用Zygote.forkAndSpecialize()来fork出新进程,之后会通过RuntimeInit.nativeZygoteInit来初始化Andriod APP运行需要的一些环境,而binder线程就是在这个时候新建启动的,看下面的源码(Android 4.3):
这里不分析Zygote,只是给出其大概运行机制,Zygote在启动后,就会通过runSelectLoop不断的监听socket,等待请求来fork进程,如下:
1 | private static void runSelectLoop() throws MethodAndArgsCaller { |
每次fork请求到来都会调用ZygoteConnection的runOnce()来处理请求,
1 | boolean runOnce() throws ZygoteInit.MethodAndArgsCaller { |
runOnce()有两个关键点,关键点1 Zygote.forkAndSpecialize就是通过fork系统调用来新建进程,关键点2 handleChildProc就是对新建的APP进程进行一些初始化工作,为Android Java进程创建一些必须的场景。Zygote.forkAndSpecialize没什么可看的,就是Linux中的fork进程,这里主要看一下handleChildProc
1 | private void handleChildProc(Arguments parsedArgs, |
接着看 RuntimeInit.zygoteInit函数
1 | public static final void zygoteInit(int targetSdkVersion, String[] argv) |
先看关键点1,nativeZygoteInit属于Native方法,该方法位于AndroidRuntime.cpp中,其实就是调用调用到app_main.cpp中的onZygoteInit
1 | static void com_android_internal_os_RuntimeInit_nativeZygoteInit(JNIEnv* env, jobject clazz) |
关键就是onZygoteInit
1 | virtual void onZygoteInit() |
首先,ProcessState::self()函数会调用open()打开/dev/binder设备,这个时候Client就能通过Binder进行远程通信;其次,proc->startThreadPool()负责新建一个binder线程,监听Binder设备,这样进程就具备了作为Binder服务端的资格。每个APP的进程都会通过onZygoteInit打开Binder,既能作为Client,也能作为Server,这就是Android进程天然支持Binder通信的原因。
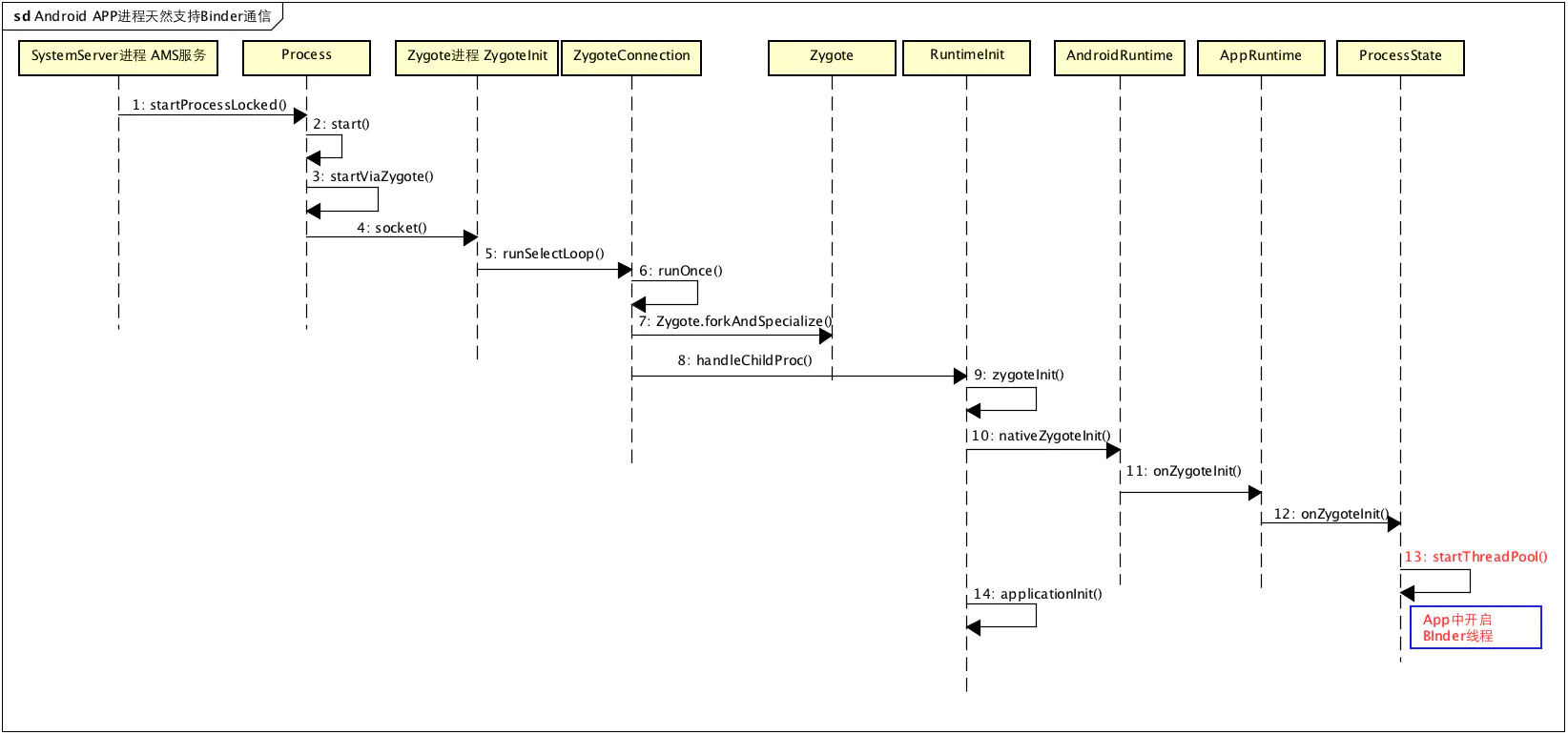
Android APP进程天然支持Binder通信.png
Android APP有多少Binder线程,是固定的么?
通过上一个问题我们知道了Android APP线程为什么天然支持Binder通信,并且可以作为Binder的Service端,同时也对Binder线程有了一个了解,那么在一个Android APP的进程里面究竟有多少个Binder线程呢?是固定的吗。在分析上一个问题的时候,我们知道Android APP进程在Zygote fork之初就为它新建了一个Binder主线程,使得APP端也可以作为Binder的服务端,这个时候Binder线程的数量就只有一个,假设我们的APP自身实现了很多的Binder服务,一个线程够用的吗?这里不妨想想一下SystemServer进程,SystemServer拥有很多系统服务,一个线程应该是不够用的,如果看过SystemServer代码可能会发现,对于Android4.3的源码,其实一开始为该服务开启了两个Binder线程。还有个分析Binder常用的服务,media服务,也是在一开始的时候开启了两个线程。
先看下SystemServer的开始加载的线程:通过 ProcessState::self()->startThreadPool()新加了一个Binder线程,然后通过IPCThreadState::self()->joinThreadPool();将当前线程变成Binder线程,注意这里是针对Android4.3的源码,android6.0的这里略有不同。
1 | extern "C" status_t system_init() |
再看下Media服务,同SystemServer类似,也是开启了两个Binder线程:
1 | int main(int argc, char** argv) |
可以看出Android APP上层应用的进程一般是开启一个Binder线程,而对于SystemServer或者media服务等使用频率高,服务复杂的进程,一般都是开启两个或者更多。来看第二个问题,Binder线程的数目是固定的吗?答案是否定的,驱动会根据目标进程中是否存在足够多的Binder线程来告诉进程是不是要新建Binder线程,详细逻辑,首先看一下新建Binder线程的入口:
1 | status_t IPCThreadState::executeCommand(int32_t cmd) |
executeCommand一定是从Bindr驱动返回的BR命令,这里是BR_SPAWN_LOOPER,什么时候,Binder驱动会向进程发送BR_SPAWN_LOOPER呢?全局搜索之后,发现只有一个地方binder_thread_read,如果直观的想一下,什么时候需要新建Binder线程呢?很简单,不够用的时候,注意上面使用的是spawnPooledThread(false),也就是说这里启动的都是普通Binder线程。为了了解启动时机,先看一些binder_proc内部判定参数的意义:
1 | struct binder_proc { |
再来看binder_thread_read函数中是么时候会去请求新建Binder线程,以Android APP进程为例子,通过前面的分析知道APP进程天然支持Binder通信,因为它有一个Binder主线程,启动之后就会阻塞等待Client请求,这里会更新proc->ready_threads,第一次阻塞等待的时候proc->ready_threads=1,之后睡眠。
1 | binder_thread_read(){ |
被Client唤醒后proc->ready_threads会-1,之后变成0,这样在执行到done的时候,就会发现proc->requested_threads + proc->ready_threads == 0,这是新建Binder线程的一个必须条件,再看下其他几个条件
1 | if (proc->requested_threads + proc->ready_threads == 0 && |
- proc->requested_threads + proc->ready_threads == 0 :如果目前还没申请新建Binder线程,并且proc->ready_threads空闲Binder线程也是0,就需要新建一个Binder线程,其实就是为了保证有至少有一个空闲的线程。
- proc->requested_threads_started < proc->max_threads:目前启动的普通Binder线程数requested_threads_started还没达到上限(默认APP进程是15)
- thread->looper & (BINDER_LOOPER_STATE_REGISTERED | BINDER_LOOPER_STATE_ENTERED) 当先线程是Binder线程,这个是一定满足的,不知道为什么列出来
proc->max_threads是多少呢?不同的进程其实设置的是不一样的,看普通的APP进程,在ProcessState::self()新建ProcessState单利对象的时候会调用ioctl(fd, BINDER_SET_MAX_THREADS, &maxThreads);设置上限,可以看到默认设置的上限是15。
1 | static int open_driver() |
如果满足新建的条件,就会将proc->requested_threads加1,并在驱动执行完毕后,利用put_user(BR_SPAWN_LOOPER, (uint32_t __user *)buffer);通知服务端在用户空间发起新建Binder线程的操作,新建的是普通Binder线程,最终再进入binder_thread_write的BC_REGISTER_LOOPER:
1 | int binder_thread_write(struct binder_proc *proc, struct binder_thread *thread, |
这里会将proc->requested_threads复原,其实就是-1,并且启动的Binder线程数+1。
个人理解,之所以采用动态新建Binder线程的意义有两点,第一:如果没有Client请求服务,就保持线程数不变,减少资源浪费,需要的时候再分配新线程。第二:有请求的情况下,保证至少有一个空闲线程是给Client端,以提高Server端响应速度。
不过这里有一点要注意,对于同一个线程的请求,如果是阻塞的,那么没什么问题,肯定是等待上一个请求结束才能处理下一个,但是对于oneway方式的binder请求呢,这里就会存在这么一个场景,对于oneway的请求,如果上一个还没处理完,同一个线程的新的oneway请求会被塞到同一个目标线程等待执行,而不会触发创建新的Binder线程,因为这并不会妨碍另一端的处理,因为它压根无需等待,但是这可能会造成服务端单个线程任务繁重,而其他线程保持空闲,不过在一定程度上实现了同一种任务的顺序执行,可能也有一定的好处吧。
同一个线程的请求必定是顺序执行,即使是异步请求(oneway)
一般而言,Client同步阻塞请求Service,直到Service提供完服务后才返回,不过,也有特殊的,比如请求用ONE_WAY方式,这种场景一般主要是用来通知,至于通知被谁消费,是否被消费压根不会关心。拿ContentService服务为例子,它是一个全局的通知中心,负责转发通知,而且,一般是群发,由于在转发的时候,ContentService被看做Client,如果这个时候采用普通的同步阻塞势必会造成通知的延时发送,所以这里的Client采用了oneway,异步。
1 | interface IContentObserver |
这种机制可能也会影响Service的性能,比如同一个线程中的Client请求的服务是一个耗时操作的时候,通过oneway的方式发送请求的话,如果之前的请求还没被执行完,则Service不会启动新的线程去响应,该请求线程的所有操作都会被放到同一个Binder线程中依次执行,这样其实没有利用Binder机制的动态线程池,如果是多个线程中的Client并发请求,则还是会动态增加Binder线程的,大概这个是为了保证同一个线程中的Binder请求要依次执行吧,这种表现好像是反过来了,Client异步,而Service阻塞了,也就是说虽然解决了Client请求不被阻塞的问题,但是请求的处理并未被加速。
Client端线程睡眠在哪个队列上,唤醒Server端哪个等待队列上的线程
先看第一部分:发送端线程睡眠在哪个队列上?
发送端线程一定睡眠在自己binder_thread的等待队列上,并且,该队列上有且只有自己一个睡眠线程
再看第二部分:在Binder驱动去唤醒线程的时候,唤醒的是哪个等待队列上的线程?
理解这个问题需要理解binder_thread中的 struct binder_transaction * transaction_stack栈,这个栈规定了transaction的执行顺序:栈顶的一定先于栈内执行。
如果本地操作是BC_REPLY,一定是唤醒之前发送等待的线程,这个是100%的,但是如果是BC_TRANSACTION,那就不一定了,尤其是当两端互为服务相互请求的时候,场景如下:
- 进程A的普通线程AT1请求B进程的B1服务,唤醒B进程的Binder线程,AT1睡眠等待服务结束
- B进程的B1服务在执行的的时候,需要请求进程A的A1服务,则B进程的Binder线程BT1睡眠,等待服务结束。
这个时候就会遇到一个问题:唤醒哪个线程比较合适?是睡眠在进程队列上的线程,还是之前睡眠的线程AT1?答案是:之前睡眠等待B服务返回的线程AT1,具体看下面的图解分析
首先第一步A普通线程去请求B进程的B1服务,这个时候在A进程的AT1线程的binder_ref中会将binder_transaction1入栈,而同样B的Binder线程在读取binder_work之后,也会将binder_transaction1加入自己的堆栈,如下图:
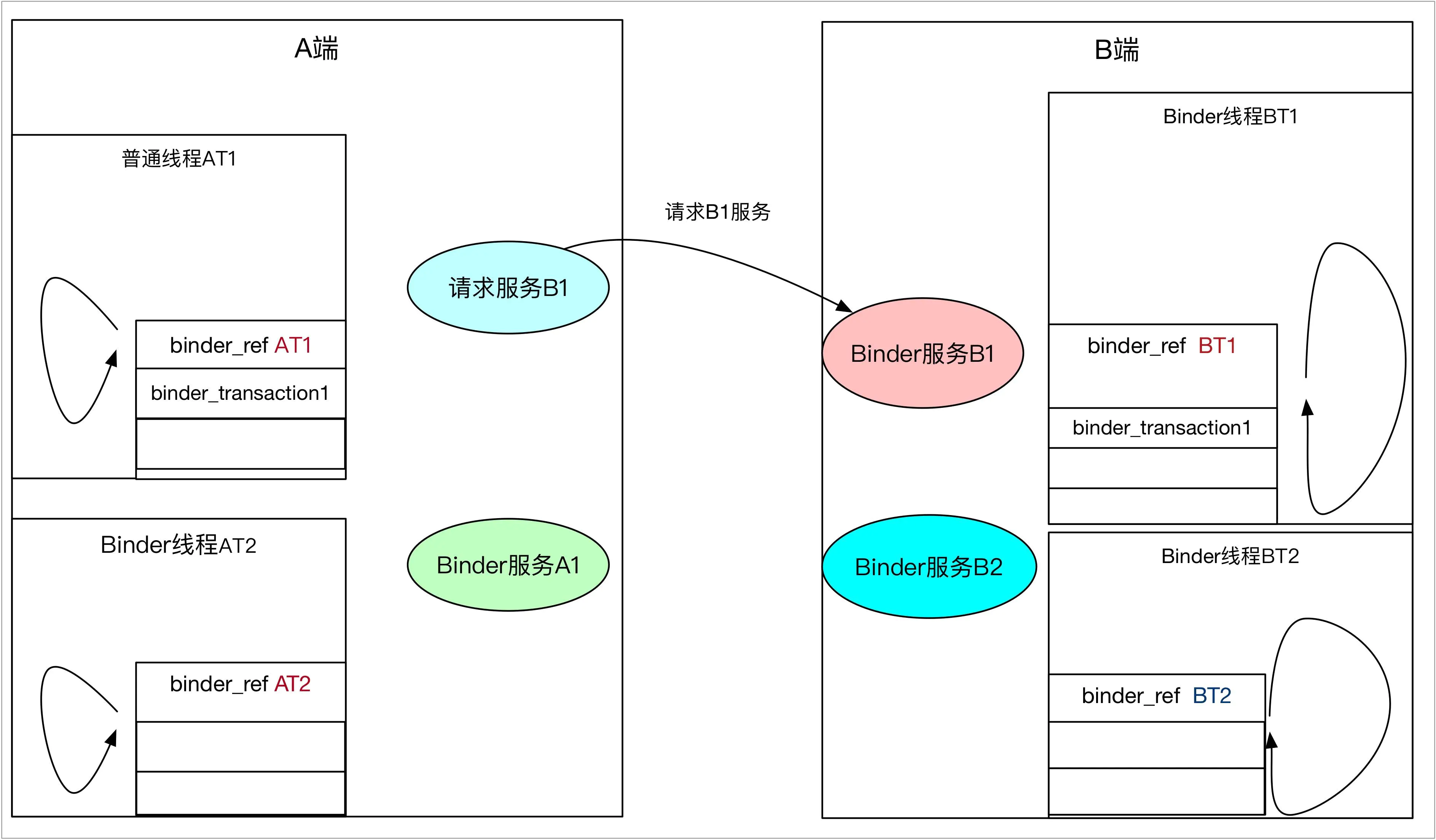
binder_transaction堆栈及唤醒那个队列1.jpg
而当B的Binder线程被唤醒后,执行Binder实体中的服务时,发现服务函数需要反过来去请求A端的A1服务,那就需要通过Binder向A进程发送请求,并新建binder_transaction2压入自己的binder_transaction堆栈,这个没有任何问题。但是,在A端入栈的时候,会面临一个抉择,写入那个队列?是binder_proc上的队列,还是正在等候B1服务返回的AT1线程的队列?
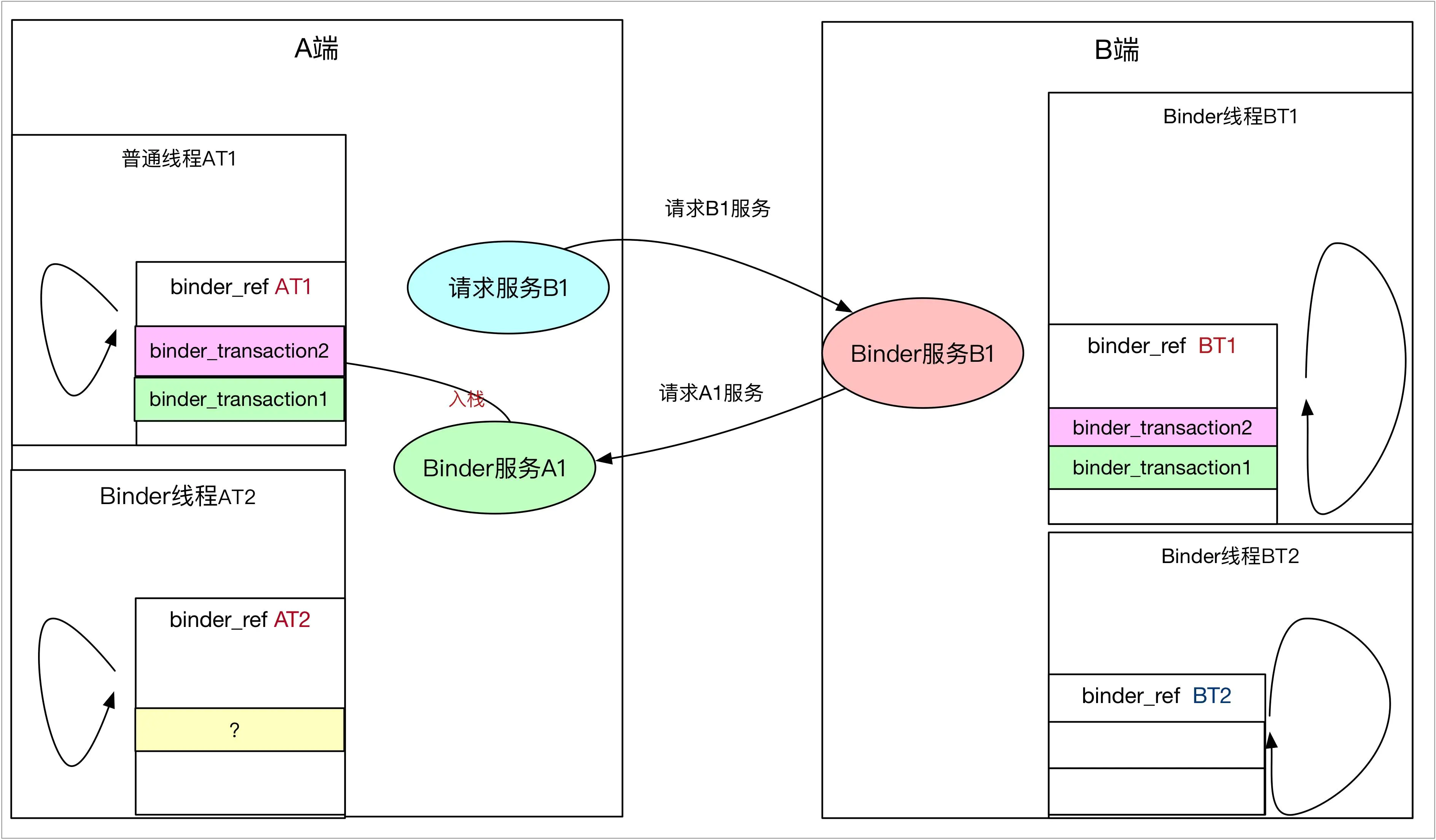
binder_transaction堆栈及唤醒那个队列2.jpg
结果已经说过,是AT1的队列,为什么呢?因为AT1队列上的之前的binder_transaction1在等待B进程执行完,但是B端执行binder_transaction1时候,需要等待binder_transaction2执行完,也就是说,在binder_transaction2执行完毕前,A端的binder_transaction1一定是不会被执行的,也就是线程AT1在B执行binder_transaction2的时候,一定是空闲的,那么,不妨唤醒AT1线程,让它帮忙执行完binder_transaction2,执行完之后,AT1又会睡眠等待B端返回,这样,既不妨碍binder_transaction1的执行,同样也能提高AT1线程利用率,出栈的过程其实就简单了,
- AT1 执行binder_transaction2,唤醒B端BT1 Binder线程,并且AT1继续睡眠(因为还有等待的transaction)
- BT1 处理binder_transaction2结果,并执行完binder_transaction1,唤醒AT1
- AT1处理binder_transaction1返回结果 执行结束
不妨再深入一点,如果A端binder_transaction2又需要B进程B2服务,这个时候是什么效果唤醒谁,答案是BT1,这就杜绝了两端循环请求的,不断增加线程池容量。
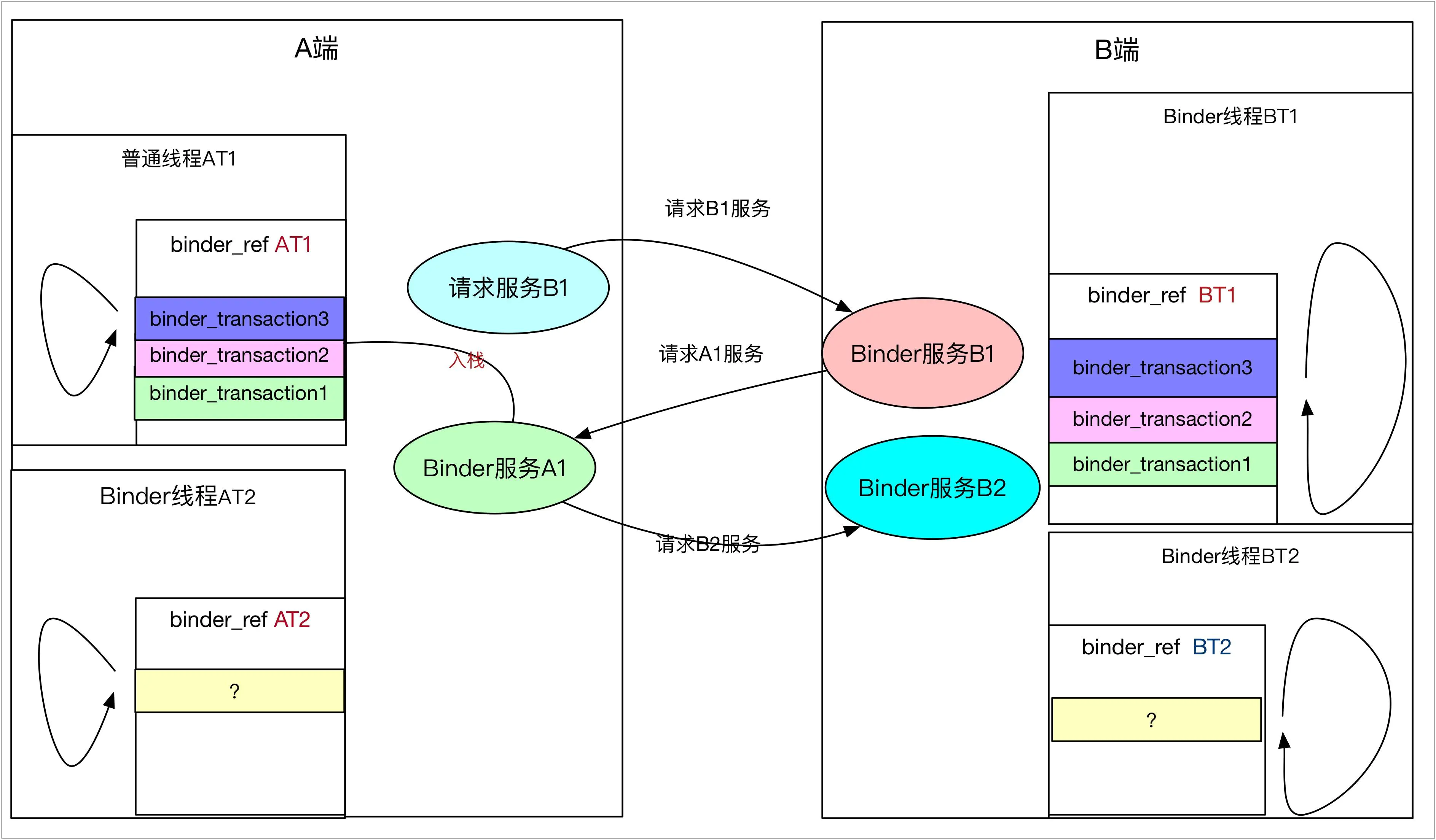
binder_transaction堆栈及唤醒那个队列3.jpg
从这里可以看出,Binder其实设计的还是很巧妙的,让线程复用,提高了效率,还避免了新建不必要的Binder线程,这段优化在binder驱动实现代码如下:其实就是根据binder_transaction记录,处理入栈唤醒问题
1 | static void binder_transaction(struct binder_proc *proc, |
Binder协议中BC与BR的区别
BC与BR主要是标志数据及Transaction流向,其中BC是从用户空间流向内核,而BR是从内核流线用户空间,比如Client向Server发送请求的时候,用的是BC_TRANSACTION,当数据被写入到目标进程后,target_proc所在的进程被唤醒,在内核空间中,会将BC转换为BR,并将数据与操作传递该用户空间。
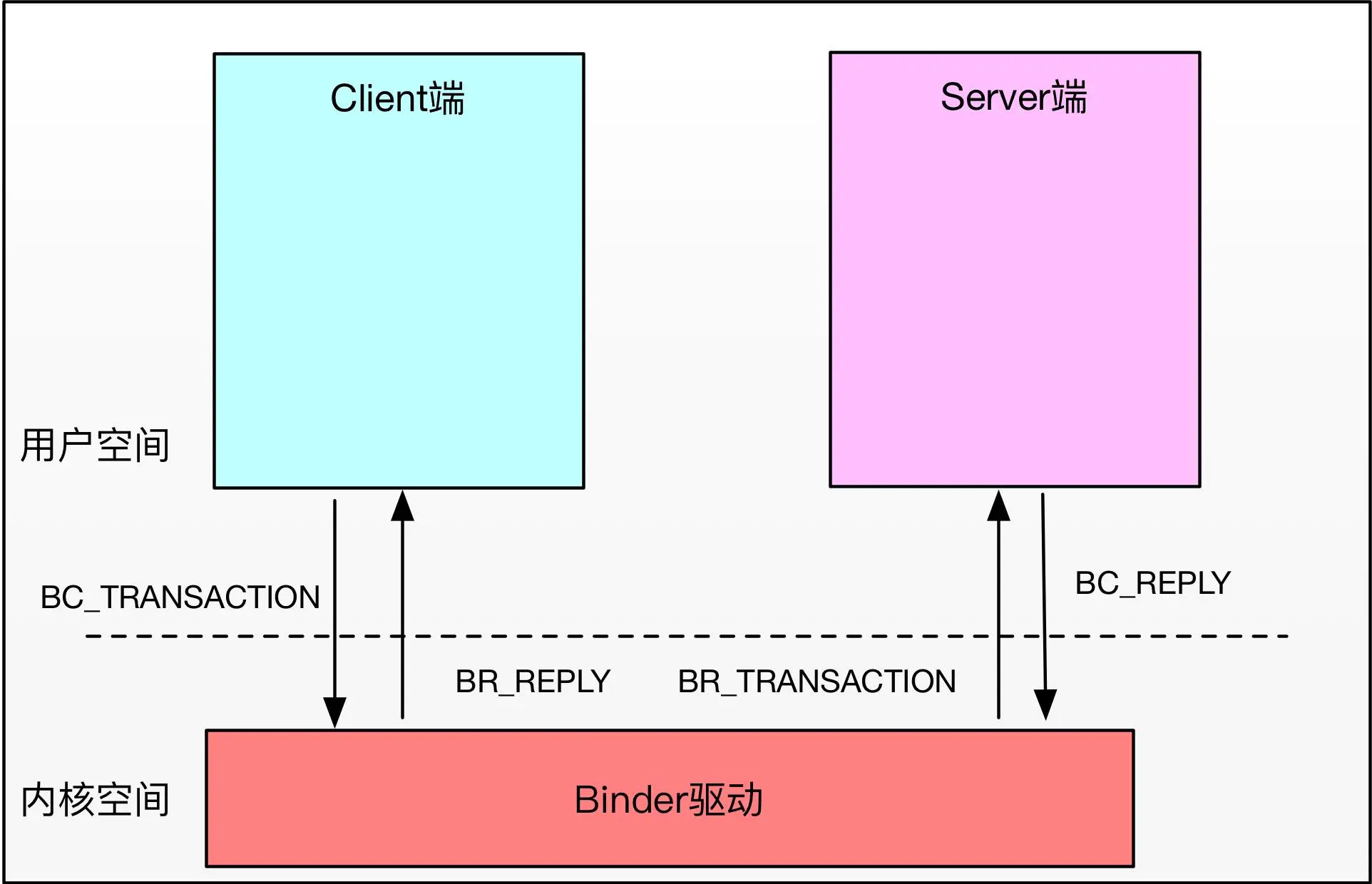
BR与BC区别
Binder在传输数据的时候是如何层层封装的–不同层次使用的数据结构(命令的封装)
内核中,与用户空间对应的结构体对象都需要新建,但传输数据的数据只拷贝一次,就是一次拷贝的时候。
从Client端请求开始分析,暂不考虑java层,只考虑Native,以ServiceManager的addService为例,具体看一下
1 | MediaPlayerService::instantiate(); |
MediaPlayerService会新建Binder实体,并将其注册到ServiceManager中:
1 | void MediaPlayerService::instantiate() { |
这里defaultServiceManager其实就是获取ServiceManager的远程代理:
1 | sp<IServiceManager> defaultServiceManager() |
如果将代码简化其实就是
1 | return gDefaultServiceManager = BpServiceManager (new BpBinder(0)); |
addService就是调用BpServiceManager的addService,
1 | virtual status_t addService(const String16& name, const sp<IBinder>& service, |
这里会开始第一步的封装,数据封装,其实就是讲具体的传输数据写入到Parcel对象中,与Parcel对应是ADD_SERVICE_TRANSACTION等具体操作。比较需要注意的就是data.writeStrongBinder,这里其实就是把Binder实体压扁:
1 | status_t Parcel::writeStrongBinder(const sp<IBinder>& val) |
具体做法就是转换成flat_binder_object,以传递Binder的类型、指针之类的信息:
1 | status_t flatten_binder(const sp<ProcessState>& proc, |
接下来看 remote()->transact(ADD_SERVICE_TRANSACTION, data, &reply); 在上面的环境中,remote()函数返回的就是BpBinder(0),
1 | status_t BpBinder::transact( |
之后通过 IPCThreadState::self()->transact( mHandle, code, data, reply, flags)进行进一步封装:
1 | status_t IPCThreadState::transact(int32_t handle, |
writeTransactionData(BC_TRANSACTION, flags, handle, code, data, NULL);是进一步封装的入口,在这个函数中Parcel& data、handle、code、被进一步封装成binder_transaction_data对象,并拷贝到mOut的data中去,同时也会将BC_TRANSACTION命令也写入mOut,这里与binder_transaction_data对应的CMD是BC_TRANSACTION,binder_transaction_data也存储了数据的指引新信息:
1 | status_t IPCThreadState::writeTransactionData(int32_t cmd, uint32_t binderFlags, |
mOut封装结束后,会通过waitForResponse调用talkWithDriver继续封装:
1 | status_t IPCThreadState::talkWithDriver(bool doReceive) |
talkWithDriver会将mOut中的数据与命令继续封装成binder_write_read对象,其中bwr.write_buffer就是mOut中的data(binder_transaction_data+BC_TRRANSACTION),之后就会通过ioctl与binder驱动交互,进入内核,这里与binder_write_read对象对应的CMD是BINDER_WRITE_READ,进入驱动后,是先写后读的顺序,所以才叫BINDER_WRITE_READ命令,与BINDER_WRITE_READ层级对应的几个命令码一般都是跟线程、进程、数据整体传输相关的操作,不涉及具体的业务处理,比如BINDER_SET_CONTEXT_MGR是将线程编程ServiceManager线程,并创建0号Handle对应的binder_node、BINDER_SET_MAX_THREADS是设置最大的非主Binder线程数,而BINDER_WRITE_READ就是表示这是一次读写操作:
1 |
|
详细看一下binder_ioctl对于BINDER_WRITE_READ的处理,
1 | static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg) |
binder_thread_write(proc, thread, (void __user )bwr.write_buffer, bwr.write_size, &bwr.write_consumed)这里其实就是把解析的binder_write_read对象再剥离,*bwr.write_buffer 就是上面的(BC_TRANSACTION+ binder_transaction_data),
1 | int binder_thread_write(struct binder_proc *proc, struct binder_thread *thread, |
binder_thread_write会进一步根据CMD剥离出binder_transaction_data tr,交给binder_transaction处理,其实到binder_transaction数据几乎已经剥离极限,剩下的都是业务相关的,但是这里牵扯到一个Binder实体与Handle的转换过程,同城也牵扯两个进程在内核空间共享一些数据的问题,因此这里又进行了一次进一步的封装与拆封装,这里新封装了连个对象 binder_transaction与binder_work,有所区别的是binder_work可以看做是进程私有,但是binder_transaction是两个交互的进程共享的:binder_work是插入到线程或者进程的work todo队列上去的:
1 | struct binder_thread { |
这里主要关心一下binder_transaction:binder_transaction主要记录了当前transaction的来源,去向,同时也为了返回做准备,buffer字段是一次拷贝后数据在Binder的内存地址。
1 | struct binder_transaction { |
binder_transaction函数主要负责的工作:
新建binder_transaction对象,并插入到自己的binder_transaction堆栈中
新建binder_work对象,插入到目标队列
Binder与Handle的转换 (flat_binder_object)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply)
{
struct binder_transaction *t;
struct binder_work *tcomplete;
size_t *offp, *off_end;
struct binder_proc *target_proc;
struct binder_thread *target_thread = NULL;
struct binder_node *target_node = NULL;
**关键点1**
if (reply) {
in_reply_to = thread->transaction_stack;
thread->transaction_stack = in_reply_to->to_parent;
target_thread = in_reply_to->from;
target_proc = target_thread->proc;
}else {
if (tr->target.handle) {
struct binder_ref * ref;
ref = binder_get_ref(proc, tr->target.handle);
target_node = ref->node;
} else {
target_node = binder_context_mgr_node;
}
..。
**关键点2**
t = kzalloc(sizeof( * t), GFP_KERNEL);
...
tcomplete = kzalloc(sizeof(*tcomplete), GFP_KERNEL);
**关键点3 **
off_end = (void *)offp + tr->offsets_size;
for (; offp < off_end; offp++) {
struct flat_binder_object *fp;
fp = (struct flat_binder_object *)(t->buffer->data + *offp);
switch (fp->type) {
case BINDER_TYPE_BINDER:
case BINDER_TYPE_WEAK_BINDER: {
struct binder_ref *ref;
struct binder_node *node = binder_get_node(proc, fp->binder);
if (node == NULL) {
node = binder_new_node(proc, fp->binder, fp->cookie);
}..
ref = (target_proc, node); if (fp->type == BINDER_TYPE_BINDER)
fp->type = BINDER_TYPE_HANDLE;
else
fp->type = BINDER_TYPE_WEAK_HANDLE;
fp->handle = ref->desc;
} break;
case BINDER_TYPE_HANDLE:
case BINDER_TYPE_WEAK_HANDLE: {
struct binder_ref *ref = binder_get_ref(proc, fp->handle);
if (ref->node->proc == target_proc) {
if (fp->type == BINDER_TYPE_HANDLE)
fp->type = BINDER_TYPE_BINDER;
else
fp->type = BINDER_TYPE_WEAK_BINDER;
fp->binder = ref->node->ptr;
fp->cookie = ref->node->cookie;
} else {
struct binder_ref *new_ref;
new_ref = binder_get_ref_for_node(target_proc, ref->node);
fp->handle = new_ref->desc;
}
} break;
**关键点4** 将binder_work 插入到目标队列
t->work.type = BINDER_WORK_TRANSACTION;
list_add_tail(&t->work.entry, target_list);
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
list_add_tail(&tcomplete->entry, &thread->todo);
if (target_wait)
wake_up_interruptible(target_wait);
return;}
关键点1,找到目标进程,关键点2 创建binder_transaction与binder_work,关键点3 处理Binder实体与Handle转化,关键点4,将binder_work插入目标队列,并唤醒相应的等待队列,在处理Binder实体与Handle转化的时候,有下面几点注意的:
- 第一次注册Binder实体的时候,是向别的进程注册的,ServiceManager,或者SystemServer中的AMS服务
- Client请求服务的时候,一定是由Binder驱动为Client分配binder_ref,如果本进程的线程请求,fp->type = BINDER_TYPE_BINDER,否则就是fp->type = BINDER_TYPE_HANDLE。
- Android中的Parcel里面的对象一定是flat_binder_object
如此下来,写数据的流程所经历的数据结构就完了。再简单看一下被唤醒一方的读取流程,读取从阻塞在内核态的binder_thread_read开始,以传递而来的BC_TRANSACTION为例,binder_thread_read会根据一些场景添加BRXXX参数,标识驱动传给用户空间的数据流向:
1 | enum BinderDriverReturnProtocol { |
之后,read线程根据binder_transaction新建binder_transaction_data对象,再通过copy_to_user,传递给用户空间,
1 | static int |
上层通过ioctrl等待的函数被唤醒,假设现在被唤醒的是服务端,一般会执行请求,这里首先通过Parcel的ipcSetDataReference函数将数据将数据映射到Parcel对象中,之后再通过BBinder的transact函数处理具体需求;
1 | status_t IPCThreadState::executeCommand(int32_t cmd) |
这里的 b->transact(tr.code, buffer, &reply, tr.flags);就同一开始Client调用transact( mHandle, code, data, reply, flags)函数对应的处理类似,进入相对应的业务逻辑。
![]()
Binder在传输数据的时候是如何层层封装的–不同层次使用的数据结构(命令的封装.jpg
Binder驱动传递数据的释放(释放时机)
在Binder通信的过程中,数据是从发起通信进程的用户空间直接写到目标进程内核空间,而这部分数据是直接映射到用户空间,必须等用户空间使用完数据才能释放,也就是说Binder通信中内核数据的释放时机应该是用户空间控制的,内种中释放内存空间的函数是binder_free_buf,其他的数据结构其实可以直接释放掉,执行这个函数的命令是BC_FREE_BUFFER。上层用户空间常用的入口是IPCThreadState::freeBuffer:
1 | void IPCThreadState::freeBuffer(Parcel* parcel, const uint8_t* data, size_t dataSize, |
那什么时候会调用这个函数呢?在之前分析数据传递的时候,有一步是将binder_transaction_data中的数据映射到Parcel中去,其实这里是关键
1 | status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult) |
Parcel 的ipcSetDataReference函数不仅仅能讲数据映射到Parcel对象,同时还能将数据的清理函数映射进来
1 | void Parcel::ipcSetDataReference(const uint8_t* data, size_t dataSize, |
看函数定义中的release_func relFunc参数,这里就是指定内存释放函数,这里指定了IPCThreadState::freeBuffer函数,在Native层,Parcel在使用完,并走完自己的生命周期后,就会调用自己的析构函数,在其析构函数中调用了freeDataNoInit(),这个函数会间接调用上面设置的内存释放函数:
1 | Parcel::~Parcel() |
这就是数据释放的入口,进入内核空间后,执行binder_free_buf,将这次分配的内存释放,同时更新binder_proc的binder_buffer表,重新标记那些内存块被使用了,哪些没被使用。
1 | static void binder_free_buf(struct binder_proc *proc, |
Java层类似,通过JNI调用Parcel的freeData()函数释放内存,在用户空间,每次执行BR_TRANSACTION或者BR_REPLY,都会利用freeBuffer发送请求,去释放内核中的内存
ServiceManager addService的限制
并非所有服务都能通过addService添加到ServiceManager
ServiceManager其实主要的面向对象是系统服务,大部分系统服务都是由SystemServer进程总添加到ServiceManager中去的,在通过ServiceManager添加服务的时候,是有些权限校验的,源码如下:
1 | int svc_can_register(unsigned uid, uint16_t *name) |
可以看到 (uid == 0) 或者 (uid == AID_SYSTEM)的进程都是可以添加服务的,uid=0,代表root用户,而uid=AID_SYSTEM,代表系统用户 。或者是一些特殊的配置进程。SystemServer进程在被Zygote创建的时候,就被分配了UID 是AID_SYSTEM(1000),
1 | private static boolean startSystemServer() |
Android每个APP的UID,都是不同的,用了Linux的UID那一套,但是没完全沿用,这里不探讨,总之,普通的进程是没有权限注册到ServiceManager中的,那么APP平时通过bindService启动的服务怎么注册于查询的呢?接管这个任务的就是SystemServer的ActivityManagerService。
bindService启动Service与Binder服务实体的流程 (ActivityManagerService)
- bindService的框架
- binder服务实例化与转化
- 业务逻辑的唤醒
- 请求代理的转化与唤醒
bindService比startService多了一套Binder通信,其余的流程基本相同,而startService的流程,同startActivity差不多,四大组件的启动流程这里不做分析点,主要看bindService中C/S通信的建立流程,在这个流程里面,APP与服务端互为C/S的特性更明显,在APP开发的时候,binder服务是通过Service来启动的。Service的启动方式有两种startService,与bindService,这里只考虑后者,另外启动的binder服务也分为两种情况:第一种,client同server位于同一进程,可以看做内部服务,第二种,Client与Server跨进程,即使是位于同一个APP,第一桶可以不用AIDL来编写,但是第二种必须通过AIDL实现跨进程通信,看一个最简单的AIDL例子,首先在定义一个aidl接口:
IMyAidlInterface.aidl
interface IMyAidlInterface {
void communicate(int count);
}
IMyAidlInterface.aidl定义了通信的借口,通过build之后,构建工具会自动为IMyAidlInterface.aidl生成一些辅助类,这些辅助类主要作用是生成Binder通信协议框架,必须保证两方通信需要指令相同,才能解析通信内容。天王盖地虎,宝塔镇河妖。Java层Binder的对应关系Binder与BinderProxy从这里可以看出,binder采用了代理模式 stub与proxy对应,使用aidl实现的服务时候,Client如果想要获得Binder实体的代理可以通过asInterface来处理,比如如果在同一进程就是实体,不在就新建代理对象
1 | public interface IMyAidlInterface extends android.os.IInterface { |
启动Binder服务端封装Service,之所以成为封装Service,是因为Service对于Binder实体的最大作用是个作为新建服务的入口:
1 | public class AidlService extends Service { |
而启动的入口:
1 | public class MainActivity extends AppCompatActivity { |
以上四个部分就组成了AIDL跨进程服务的基本组件,现在从ActivitybindService入口开始分析:bindService大部分的流程与startActivity类似,其实都是通过AMS启动组件,这里只将一些不同的地方,Activity启动只需要Intent就可以了,而Service的bind需要一个ServiceConnection对象,这个对象其实是为了AMS端在启动Service后回调用的,ServiceConnection是个接口,其实例在ContextImpl的:
1 | private boolean bindServiceCommon(Intent service, ServiceConnection conn, int flags, |
mPackageInfo是一个LoadApk类,通过它的getServiceDispatcher获得一个IServiceConnection对象,这个对象一个Binder实体,看一下具体原理
1 | public final IServiceConnection getServiceDispatcher(ServiceConnection c, |
在LoadApk中IServiceConnection对象是通过context键值来存储ServiceDispatcher对象,而ServiceDispatcher对象内存会有个InnerConnection对象,该对象就是getServiceDispatcher的返回对象。因此bindServiceCommon最终调用
ActivityManagerNative.getDefault().bindService(x,x,x,x,x sd, x, x, x) 的时候,传递的参数sd其实就是一个InnerConnection对象,这是个Binder实体。但是,Binder.java中的Binder只是对native层BBinder的一个简单封装,真正的实例化还是通过JNI到native层去创建一个JavaBBinderHolder对象,并初始化gBinderOffsets,让其能映射Java层Binder对象,而JavaBBinderHolder中又可以实例化BBinder的实例JavaBBinder,不过BBinder的实例化时机并不在这里,而是在Parcel对象writeStrongBinder的时候,
1 | static struct bindernative_offsets_t |
继续往下看bindService,会调用到ActivityManagerProxy的bindService
1 | public int bindService(IApplicationThread caller, IBinder token, |
利用Parcel的writeStrongBinder会将Binder实体写入到Parcel中去,这里首先看一下 Parcel data = Parcel.obtain();在java层Parcel只是一个容器,具体Parcel相关的操作都在Native层
1 | static jint android_os_Parcel_create(JNIEnv* env, jclass clazz) |
这里的返回值,其实就是Parcel对象的地址,被赋值给了Parcel.java的mNativePtr成员变量,方便Native调用,接着看writeStrongBinder的实现,其实就是调用Parcel.cpp中的对应方法,通过flatten_binder将Binder实体对象打扁,创建flat_binder_object写入Parcel中,
1 | static void android_os_Parcel_writeStrongBinder(JNIEnv* env, jclass clazz, jint nativePtr, jobject object) |
ibinderForJavaObject主要为Java层Binder实例化native binder对象:
1 | sp<IBinder> ibinderForJavaObject(JNIEnv* env, jobject obj) |
如果BBinder还没实例化,要通过JavaBBinderHolder的get函数实例化一个BBinder对象,这里就是JavaBBinder对象,综上分析Java层与Native的Binder其对应关系如下:
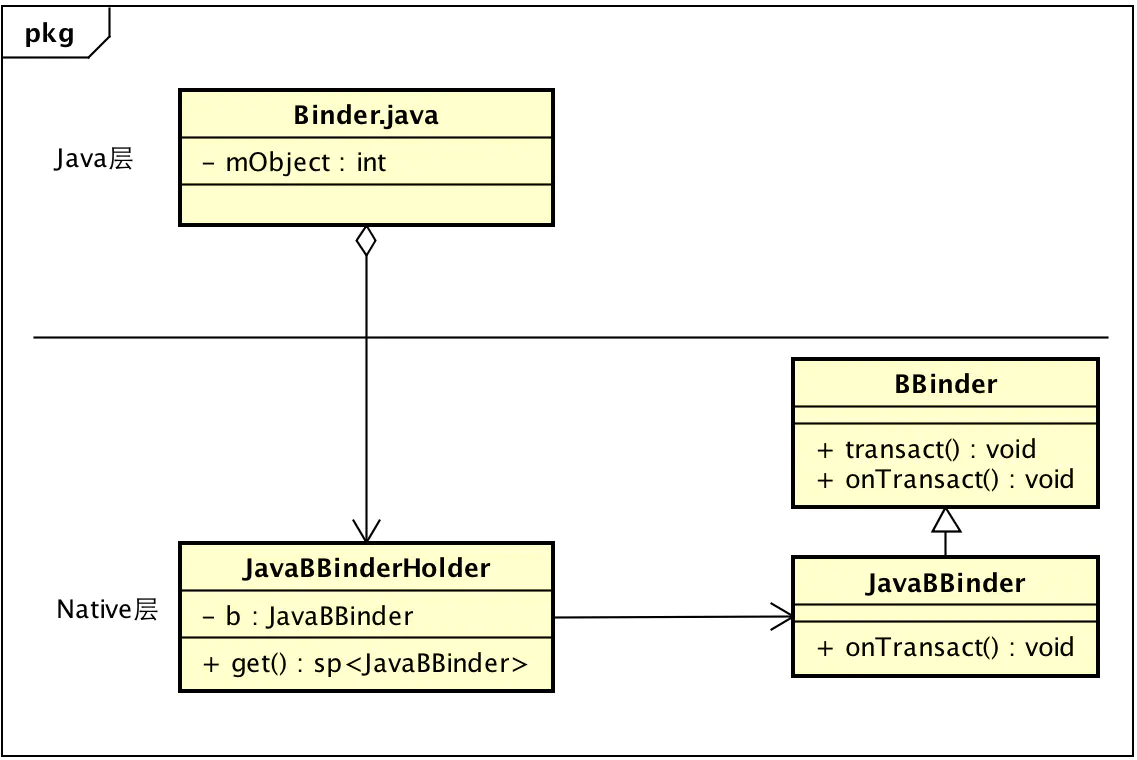
Java层Binder与native 层BBiner.png
BBinder对象被Parcel转换成flat_binder_object,经过一次拷贝写入目标进程,并执行BINDER_TYPE_BINDER与BINDER_TYPE_HANDLE的转换,如下:
1 | static void |
在内核中,bindService中的InnerConnection会由BINDER_TYPE_BINDER转换成BINDER_TYPE_HANDLE,之后,AMS线程被唤醒后,执行后面的流程,在前文分析Parcel数据转换的时候,在Binder线程被唤醒继续执行的时候,会将数据映射到一个natvie Parcel对象中
1 | status_t IPCThreadState::executeCommand(int32_t cmd) |
首先看一下关键点1 ,这里将内核数据映射到一个用户空间的Parcel对象中去,之后在调用目标Service的transact函数,进而调用他的onTrasanct函数 , 通过前面的分析知道,Java层Binder在注册时候,最终注册的是JavaBBinder对象,看一下它的onTrasanct函数:
1 | virtual status_t onTransact( |
关键代码只有一句:env->CallBooleanMethod(mObject, gBinderOffsets.mExecTransact, code, (int32_t)&data, (int32_t)reply, flags),其实就是调用Binder.java的execTransact函数,该函数首先将Native的Parcel映射成Jave层Parcel,之后调用BBinder子类的onTransact函数执行对应的业务逻辑,最后会通过data.recycle通知释放内存:
1 | private boolean execTransact(int code, int dataObj, int replyObj, |
对于AMS而bindService对应的操作如下
1 | public boolean onTransact(int code, Parcel data, Parcel reply, int flags) |
b = data.readStrongBinder()会先读取Binder对象,这里会调用本地函数nativeReadStrongBinder(mNativePtr),mNativePtr就是Native层Parcel的首地址:
1 | public final IBinder readStrongBinder() { |
nativeReadStrongBinder(mNativePtr)会将本地Binder对象转化成Java层对象,其实就是将传输的InnerConnection读取出来,不过由于Binder驱动将BINDER_TYPE_BINDER转换成了BINDER_TYPE_HANDLE,对于AMS其实是实例化BinderProxy
1 | static jobject android_os_Parcel_readStrongBinder(JNIEnv* env, jclass clazz, jint nativePtr) |
首先会利用Parcel.cpp的parcel->readStrongBinder(),读取binder对象,这里会根据flat_binder_object的类型,分别进行BBinder与BpBinder映射,如果是Binder实体直接将指针赋值out,如果不是,则根据handle获取或者新建BpBinder返回给out。
1 | status_t unflatten_binder(const sp<ProcessState>& proc, |
之后会牵扯一个将native binder转换成java层Binder的操作,javaObjectForIBinder,这个函数很关键,是理解Java层BinderProxy或者BBinder实体的关键:
1 | jobject javaObjectForIBinder(JNIEnv* env, const sp<IBinder>& val) |
先看关键点1, checkSubclass默认返回false,但是JavaBBinder,该类对此函数进行了覆盖,如果是JavaBBinder,就会返回true,但入股是BpBinder,则会返回false,
1 | bool checkSubclass(const void* subclassID) const |
再看关键点2,如果是BpBinder,则需要首先在gBinderProxyOffsets中查找,是不是已经新建了Java层代理BinderProxy对象,如果没有,则新建即可,如果新建就看是否还存在缓存有效的BinderProxy。最后看关键点3 :
1 | env->NewObject(gBinderProxyOffsets.mClass, gBinderProxyOffsets.mConstructor) |
其实就是新建BinderProxy对象,Java层的BinderProxy都是Native新建的,Java层并没有BinderProxy的新建入口,之后,再通过IServiceConnection.Stub.asInterface(b)进行转换,实例化一个IServiceConnection.Proxy代理对,该对象在Binder通信的基础上封装了业务逻辑,其实就是一些具体的操作。
1 | public static XXXAidlInterface asInterface(android.os.IBinder obj) { |
这里注意一点杜宇BinderProxy,obj.queryLocalInterface(DESCRIPTOR)返回为null,对于Binder实体,返回的是Binder自身,这样就能为上层区分出是生成代理还是存根自身,整体对象转换流程如下:
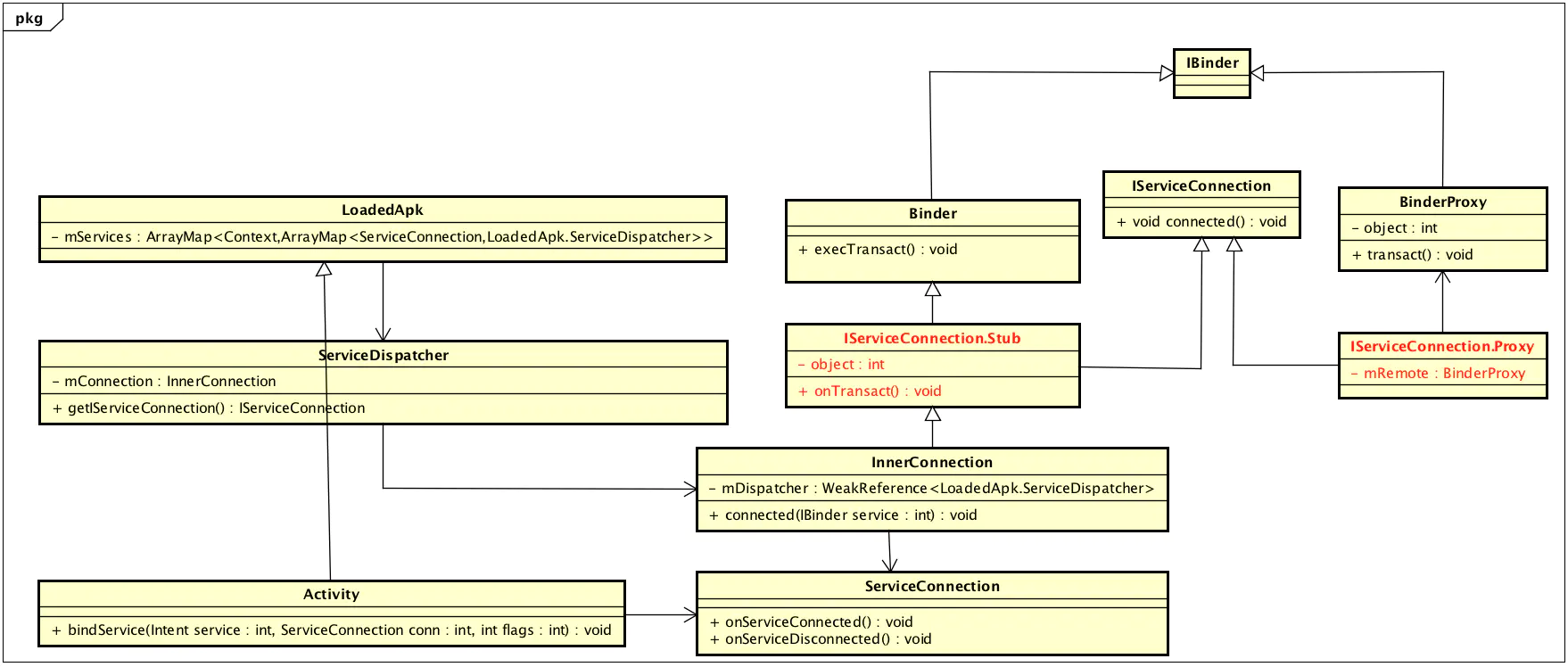
ServiceConnection的回调作用
到这里分析了一半,Java层命令及回调Binder入口已经被传递给AMS,AMS之后需要负责启动Service,并通过回调入口为Client绑定服务,跟踪到AMS源码
1 | public int bindService(IApplicationThread caller, IBinder token, |
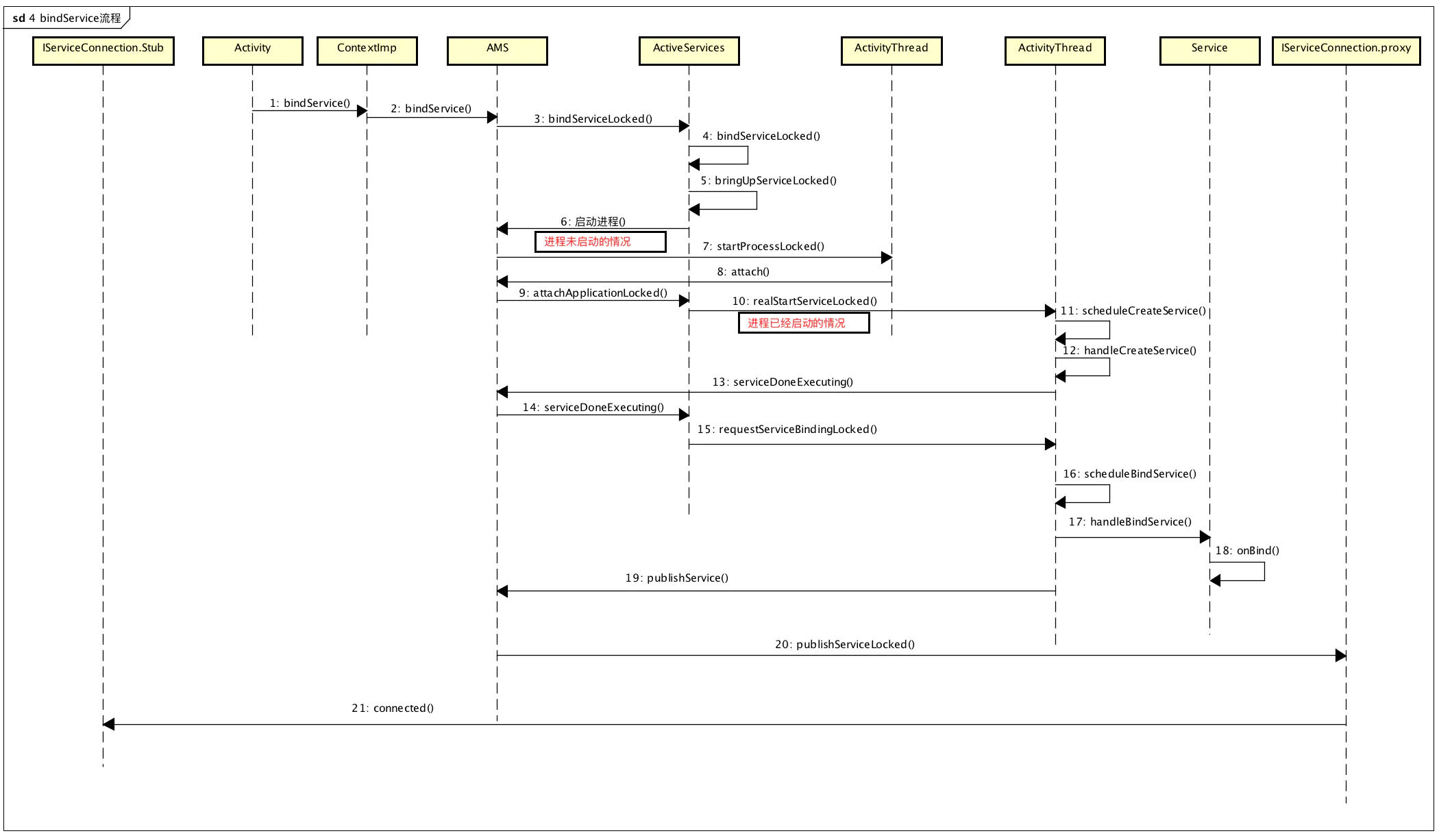
最后调用ActiveService的bindServiceLocked,这里会分三中情况,
- Service已经经启动
- Service未启动,但是进程已经启动
- Service与进程君未启动
不过这里只讨论“ Service未启动,但是进程已经启动的情况”,关键代码如下
1 | int bindServiceLocked(IApplicationThread caller, IBinder token, |
关键点1其实就是启动Service,主要是通过ApplicationThread的binder通信通知App端启动Service,这个流程同Activity启动一样。关键点2是Service特有的:requestServiceBindingLocked,这个命令是告诉APP端:“在Service启动后需要向AMS发消息,之后AMS才能向其他需要绑定该Service的Client发送反馈”。
1 | AMS端 |
ActivityManagerNative.getDefault().publishService会将启动的Binder服务实体传递给AMS,上面分析过Binder实体传输,这里的原理是一样的,AMS端在传输结束后,会获得Service端服务实体的引用,这个时候,就能通过最初的InnerConnection的回调将这个服务传递给Client端。Binder实体与引用的整体流程图如下:
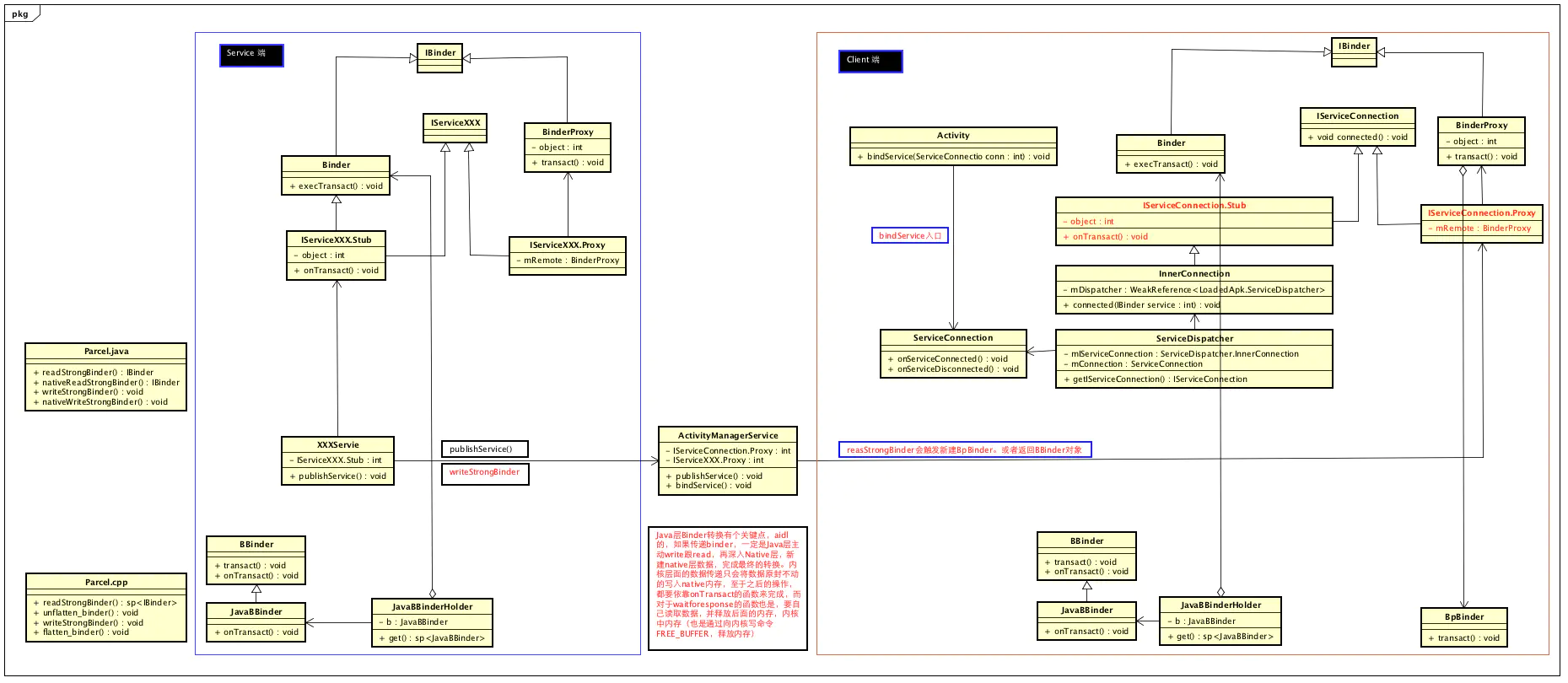
bindSerivce整体流程图
如果要深究Activity的bindService流程,可以按以下几步来分析
- 1、Activity调用bindService:通过Binder通知ActivityManagerService,要启动哪个Service
- 2、ActivityManagerService创建ServiceRecord,并利用ApplicationThreadProxy回调,通知APP新建并启动Service启动起来
- 3、ActivityManagerService把Service启动起来后,继续通过ApplicationThreadProxy,通知APP,bindService,其实就是让Service返回一个Binder对象给ActivityManagerService,以便AMS传递给Client
- 4、ActivityManagerService把从Service处得到这个Binder对象传给Activity,这里是通过IServiceConnection binder实现。
- 5、Activity被唤醒后通过Binder Stub的asInterface函数将Binder转换为代理Proxy,完成业务代理的转换,之后就能利用Proxy进行通信了。